2025-03-18
2025-03-18
Paper Reading
OpenVLA
—
Related worku
::: block VLM:
- bridge features from pretrained visual encoder(e.g. DINOv2, SigLIP) with pretrained LLM(e.g. Llama) Generalist Robot Policies:
- Octo: policy learning, compose pretrained component, learn to “stitch” them together.
- OpenVLA: end-to-end
- more generalist
- large Internet-scale dataset
- generic architecture :::
—
VLM
::: block
- visual encoder: map image inputs to image patch embeddings
- projector: align image embeddings with word embeddings
- LLM backbone :::
—
OpenVLA
::: block
- concat SigLIP+DINOv2(helpful for improving spatial reasoning)
- projector: 2-layer MLP
- use Llama 2 as backbone
- map continuous action into discrete action token.
- discretize each dimension of robot action separately into one of 256 bins.
- each bin uniformly divided into to quantile
- Training Data: Open X-Embodiment dataset :::
RT-1
—
Preliminaries
::: block Robot learning:
- Aim to learn robot policy:
- sample the action from learned distribution
- target: maximize average reward(indicate complete or not) Transformer:
- sequence model
- map image&text to action sequence Imitation Learning:
- minimize the gap between and
- refine by negative log-likelihood :::
—
System Overview
graph TB a[Textural Instruction]-->|Universal Sentence Encoder|b[word embedding vector] c[images]-->|ImageNet|d[features] b-->|FiLM|e(affine transform) d-->e e-->|Tokenizer|f[Token] f-->|Transformer|g[output Tokens] g-->|Tokenizer Decode|h[action]
RT-2
—
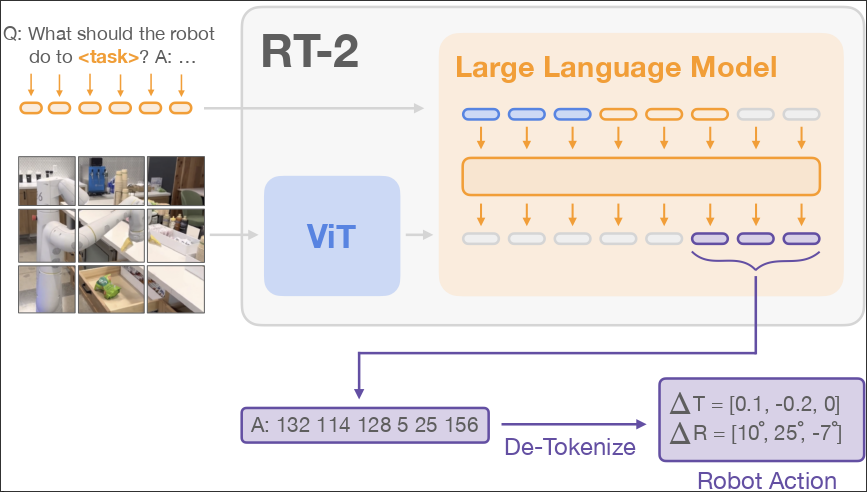
RT-2
::: block Model:
- use CLIP to tokenize images and share embeddings with text
- use PaLI-x and PaLM-E as backbone of VLM
- decode output action token :::
—
::: block Co-Fine-tuning:
- combine datasets: to enhance more generalizing policies
Output Constraint:
- only sampling robot action when prompted with a robot-action task
- otherwise, answer natural language
chain of thought:
- an additional step: Plan Step. describes the purpose of the action that the robot is about to take in natural language first
- then followed by the actual action tokens. :::
RDT-1B
—
Related work
::: block DiT:
- combine diffusion and transformer VLA:
- Vision-Language-Action Model :::
—
Problem formulation
::: block
- : RGB image history
- : low-dimensional proprioception of robot
- : control frequency
- : action, usually a subset of :::
—
Diffusion Model
::: block
- use action chunk to encourage time consistency and alleviate error accumulation over time :::
—
Encoding
::: block
- low-dimensional vectors represent physical quantities(proprioception, action chunk, control frequency)
- use MLP with Fourier Features, capture the high-frequency changes
- image input: high-dimension
- use image-text-aligned pretrained vision encoder: SigLIP
- language input:
- pretrained T5-XXL :::
—
Network Structure
::: block
- QKNorm
- RMSNorm instead of LayerNorm
- MLP Decoder instead of linear decoder
- Alternative Condition Injection :::
—
Data
Link to original ::: block ::: block Physically Interpretable Unified Action Space:
- and
- unified space ::: :::
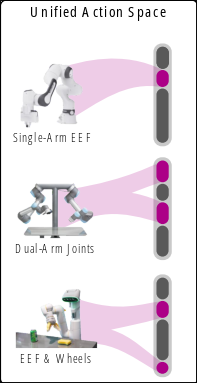
pi0
—
Related Work
::: block Flow Matching:
- denoise by conditional probability path
- loss:
Transfusion:
- train single transformer by multiple objectives
- loss: :::
—
Model
::: block
- model data distribution:
- handle action by action expert, with CFM loss:
:::
—
Train Recipe
::: block
- first pretrain on big dataset
- then fine-tune with specific task :::
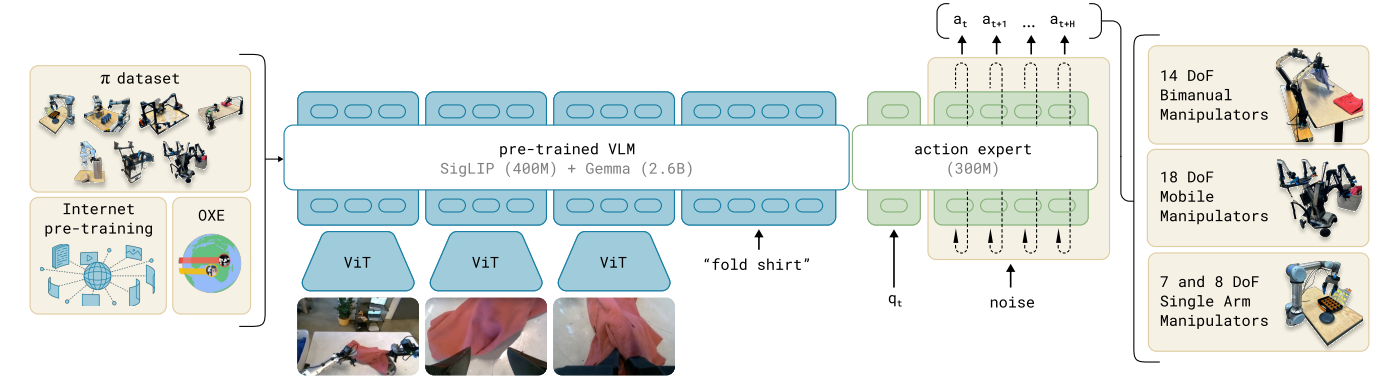
2025-04-09
2025-04-17
ReplanVLM
—
Paper
graph TB a(User Input) b(Observe Image) c(Decision Bot) d(Task plan) e(Code Generation) f(Inner Bot) g(Environment) h(Extra Bot) a-->c b-->c c-->d d-->e e-->f f-->|No|c f-->|Yes|g g-->h h-->|No|c h-->|Yes|i(end)—
- Decision Bot:
- generate task plan based on user input and observed images
- generate code based on task plan
- Inner Bot:
- check code correctness
- check with environment and codebase information
- Extra Bot:
- compare images before and after taking action
- return feedback if not succeed
Chain of Verification
—
::: block
generate baseline response by LLM
based on user input and baseline response, generate verification question for baseline response
independently answer the verification questions (w/o baseline response).
then check the answer against baseline response
generate final response based on baseline response and feedback from step 3
:::
Adaptive Interactive Navigation
—
Link to original
- Task planing:
- generate skill tree
- evaluate nodes and find high-level skeleton
- Advisor:
- interpret environment: Failure, New Object, Revaluation
- Arborist:
- adding node for new information
- pruning the failed nodes
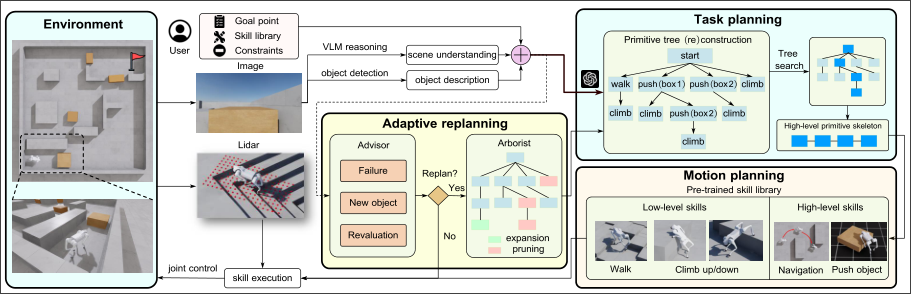
2025-04-22
2025-04-22
RL & LLM
L2R
Language to Reward for Robotic Skill Synthesis
—
Background
::: block
- MDP problem:
- reward assumption: :::
—
Method
::: block Motion Description
- use LLM to interpret and expand the user input into a natural language description of robot motion
- using prompt template
Reward Coding
- use LLM generate the reward function :::
LaRe
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
—
Motivation
::: block
- make reward include various implicit factors
(R|s_{1:T},a_{1:T})=\int\left[\underbrace{p(r_t|z_{r,t})}{\text{decoder }f}\underbrace{p(z{r,t}|s_t,a_t)}{\text{encoder }\phi}\right]p(R|r{1:T})dzdr$$
- obtain interpretable and multifaceted task performance metrics from redundant environment information :::
—
Framework
::: block
- generate responses by LLM
- summarize responses. generate code(latent reward encoder) based on summary
- verify the correctness of the encoder function
- train reward decoder with loss: $$
- optimize policy with latent reward and its decoder :::
MAYE
Rethinking RL Scaling for vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
—
Data
—
Framework
—
Algorithm
::: block
- use reward function as rule-based signal to guide RL training
- correctness
- language :::
—
Metrics
::: block Accuracy curve: correctness and effectiveness while training
Response length: length of output
Words count: effectiveness of RL training, reflected by the frequency of certain words
Ratio curves: reflective words frequency while training :::
ToRL
ToRL: Scaling Tool-integrated RL
—
TIR
::: block tool integrated reasoning
- :::
—
ToRL
::: block
- use
Qwen2.5-Math- utilize outside code interpreter to execute generated code
- concat answer with natural language response
- Design
- Tool Call Frequency Control: reduce GPU idle time
- Execution Environment Selection:
Sandbox Fusion- Error Message Processing: only last line of error message
- Sandbox Output Masking: don’t compute loss on code output :::
Some others
—
Think before you act
::: block Combine action with “caption”
- use “caption” to indicate what to do next
- use action to indicate how to do
Treat RL process as auto-regressive Transformer process :::
—
In-Context Reinforcement Learning with Algorithm Distillation
::: block Treat offline RL as sequential prediction problem, distill RL policy into Causal Sequence Model, model RL policy by Neural Network :::
Link to original
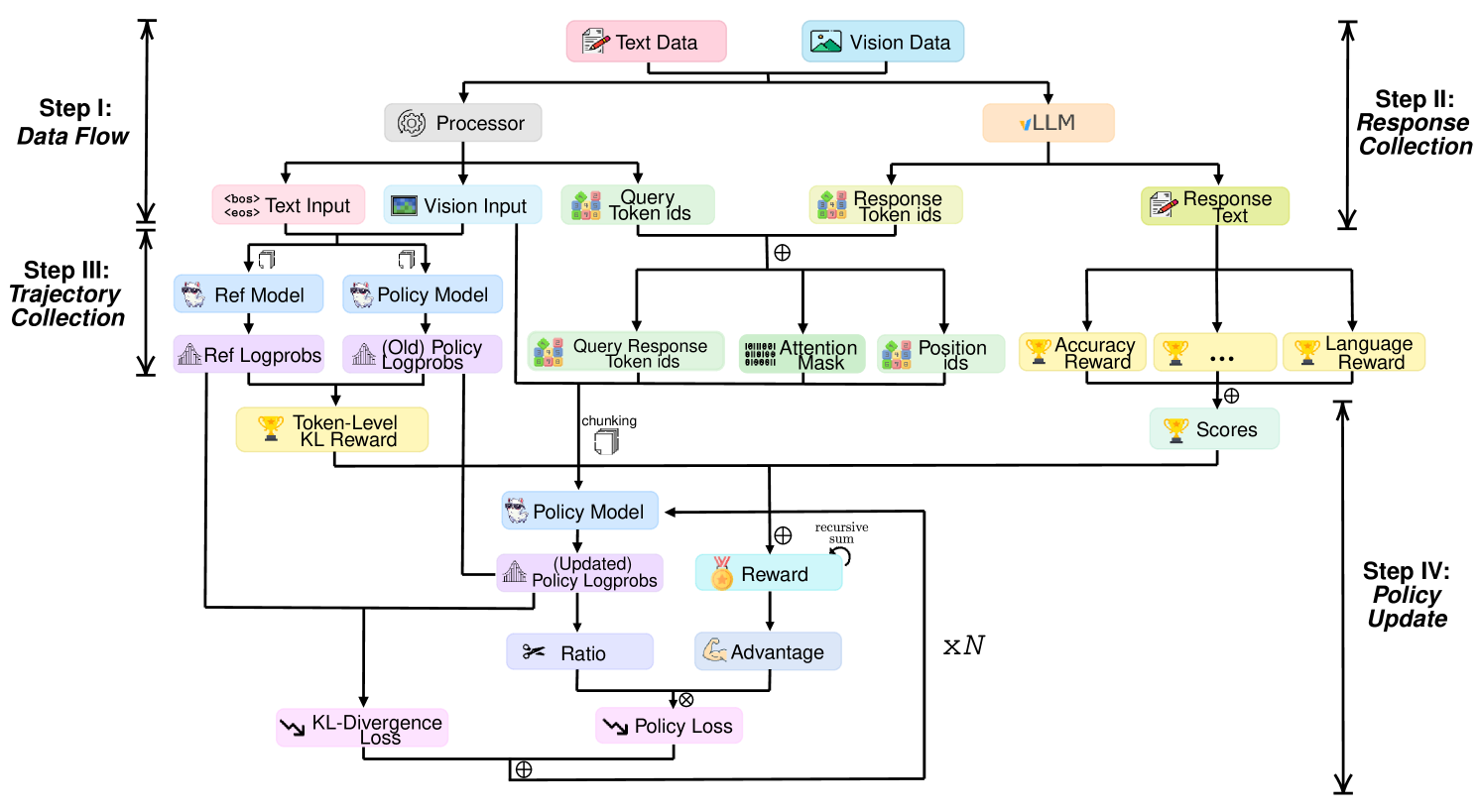
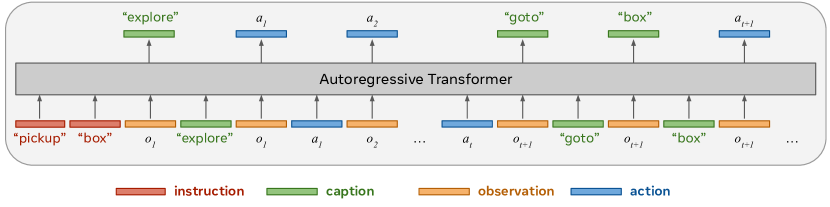
2025-04-27
2025-04-27
环境:
使用
h5py进行储存, 需要下载. 下载后位于datasets/v0.1/single_stage/kitchen_pnp/pnpcountertocab/2024-04-24/demo.hdf5f = h5py.File(os.path.join(os.getcwd(), "datasets/v0.1/single_stage/kitchen_pnp/pnpcountertocab/2024-04-24/demo.hdf5")) env_meta = json.loads(f["data"].attrs["env_args"]) states = dict(states=f["data/demo_1/states"][()][0]) states["model"] = f["data/demo_1"].attrs["model_file"] ep_meta = f["data/demo_1"].attrs.get("ep_meta", None) states["ep_meta"] = ep_meta f.close() env_kwargs = env_meta["env_kwargs"] env_kwargs["env_name"] = env_meta["env_name"] env_kwargs["has_renderer"] = False env_kwargs["renderer"] = "mjviewer" env_kwargs["has_offscreen_renderer"] = True env_kwargs["use_camera_obs"] = False # initial env env = robosuite.make(**env_kwargs) reset_to(env, state)实际上, 调用的是RoboCasa的kitchen_pnp.py里面的PnPCounterToCab环境, 通过robosuite.environments.base的MujocoEnv创建
调用:
通过
env.step(action)的方式执行单步动作.对于Panda Mobile, action space为12-dim, 有: joint旋转, 底座水平移动, 躯干上下移动, gripper开关
Link to original steps = [[0.1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ...] for step in steps: env.step(step) video_image = [] for cam in ["robot0_agentview_center"]: im = env.sim.render(camera_name=cam, width=512, height=768)[::-1] video_image.append(im) video_image = np.concatenate(video_image, axis=1) video_writer.append_data(video_image)
2025-04-29
2025-04-29
Environment Generation
使用LLM生成RL environment
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
- publish: COLM 2024
动机
- 使用LLM生成和调整多种不同的训练环境, 以增强对原始环境(不是LLM生成的环境)的表现能力
- 少量LLM的调用, 减少计算开销
环境生成
输入:
- 环境的简要描述以及LLM需要执行的操作
- 目标, LLM可以操控的环境参数, 生成中的规则约束
- 一个JSON模板, 让LLM将环境参数填到相应位置
- Agent的feedback
输出: 包含环境参数的JSON, 用于生成完整的Environment
transition和reward由原始的环境提供, LLM不参与生成
训练
进行正常的训练.
评估在原始环境中的表现情况, 计算每个目标的成功率, 并将此反馈给LLM, 用以调整下一次的生成
防止overfit到LLM生成的Environment中, 隔一定间隔对原始环境进行一次训练
RoboVerse
- 安装: 配置项比较多, 数据量大, 下载困难
- 部分代码有问题, 无法正常启动, 依赖冲突
Robocasa
robot的environment位于RoboSuite, 封装了自己的Environment
代码
def reset_to(env, state): env.set_ep_meta(json.loads(state["ep_meta"])) env.reset() xml = env.edit_model_xml(state["model"]) env.reset_from_xml_string(xml) env.sim.reset() env.sim.set_state_from_flattened(state["states"]) env.sim.forward() env.update_state() def main(): f = h5py.File(os.path.join(os.getcwd(), "datasets/v0.1/single_stage/kitchen_pnp/PnPCounterToCab/2024-04-24/demo.hdf5")) env_meta = json.loads(f["data"].attrs["env_args"]) states = dict(states=f["data/demo_1/states"][()][0]) states["model"] = f["data/demo_1"].attrs["model_file"] ep_meta = f["data/demo_1"].attrs.get("ep_meta", None) states["ep_meta"] = ep_meta f.close() env_kwargs = env_meta["env_kwargs"] env_kwargs["env_name"] = env_meta["env_name"] env_kwargs["has_renderer"] = False env_kwargs["renderer"] = "mjviewer" env_kwargs["has_offscreen_renderer"] = True env_kwargs["use_camera_obs"] = False print(json.dumps(env_kwargs, indent=4)) path = f"./video_result/video_{len(os.listdir('./video_result'))}.mp4" video_writer = imageio.get_writer(path, fps=50) # initial env env = robosuite.make(**env_kwargs) reset_to(env, states) steps = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ...] for step in steps: _ret = env.step(step) video_image = [] for cam in ["robot0_agentview_center"]: im = env.sim.render(camera_name=cam, width=512, height=768)[::-1] video_image.append(im) video_image = np.concatenate(video_image, axis=1) video_writer.append_data(video_image) video_writer.close() env.close()实际调用: robosuite的make方法创建一个环境, 配置参数由dataset定义
- env_name: 创建的环境名字
- robots: 包含的robot, robosuite支持多机器人, 但是robocasa的kitchen只支持一个机器人
- controller_configs: 包含mujoco的controller的配置(kp, limits等等)
当前进度:
- 已完成panda mobile robot的操控
- 即将完成G1 robot的集成
未来计划:
Link to original
- 添加G1 robot的controller config, 完成G1 robot的集成
- 测试G1 robot
- 尝试进行RL的训练
2025-05-13
2025-05-21
2025-05-29
2025-06-11
2025-06-18