RL & LLM
L2R
Language to Reward for Robotic Skill Synthesis
—
Background
::: block
- MDP problem:
- reward assumption: :::
—
Method
::: block Motion Description
- use LLM to interpret and expand the user input into a natural language description of robot motion
- using prompt template
Reward Coding
- use LLM generate the reward function :::
LaRe
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
—
Motivation
::: block
- make reward include various implicit factors
(R|s_{1:T},a_{1:T})=\int\left[\underbrace{p(r_t|z_{r,t})}{\text{decoder }f}\underbrace{p(z{r,t}|s_t,a_t)}{\text{encoder }\phi}\right]p(R|r{1:T})dzdr$$
- obtain interpretable and multifaceted task performance metrics from redundant environment information :::
—
Framework
::: block
- generate responses by LLM
- summarize responses. generate code(latent reward encoder) based on summary
- verify the correctness of the encoder function
- train reward decoder with loss: $$
- optimize policy with latent reward and its decoder :::
MAYE
Rethinking RL Scaling for vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
—
Data
—
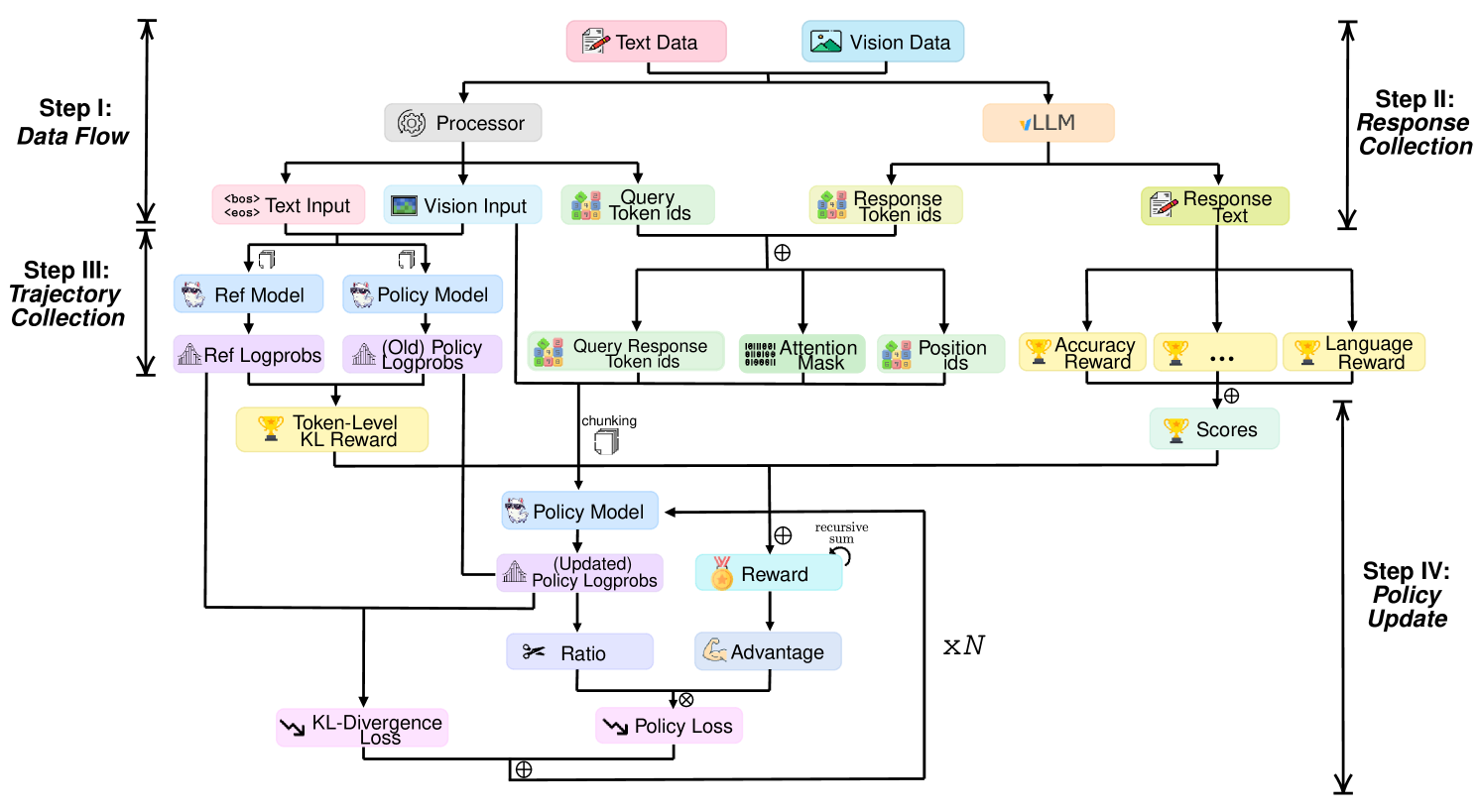
Framework
—
Algorithm
::: block
- use reward function as rule-based signal to guide RL training
- correctness
- language :::
—
Metrics
::: block Accuracy curve: correctness and effectiveness while training
Response length: length of output
Words count: effectiveness of RL training, reflected by the frequency of certain words
Ratio curves: reflective words frequency while training :::
ToRL
ToRL: Scaling Tool-integrated RL
—
TIR
::: block tool integrated reasoning
- :::
—
ToRL
::: block
- use
Qwen2.5-Math - utilize outside code interpreter to execute generated code
- concat answer with natural language response
- Design
- Tool Call Frequency Control: reduce GPU idle time
- Execution Environment Selection:
Sandbox Fusion - Error Message Processing: only last line of error message
- Sandbox Output Masking: don’t compute loss on code output :::
Some others
—
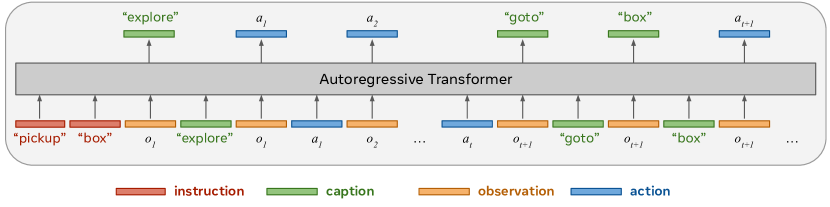
Think before you act
::: block Combine action with “caption”
- use “caption” to indicate what to do next
- use action to indicate how to do
Treat RL process as auto-regressive Transformer process :::
—
In-Context Reinforcement Learning with Algorithm Distillation
::: block Treat offline RL as sequential prediction problem, distill RL policy into Causal Sequence Model, model RL policy by Neural Network :::