LESR
Paper
Introduce
问题: source state repr通常包含general的环境信息, 但是缺少关于当前任务的特定细节信息, 这些信息可能对value network的训练起到重要作用
使用LLM增强state的表达, 获取内在隐藏的表达, 增强value network从state到reward的准确性
提出LLM-Empowered State Representation(LESR), 利用LLM编码能力和对物理世界的解释能力来生成task-related state representation. 然后, LLM利用生成的state repr生成reward函数.
Method
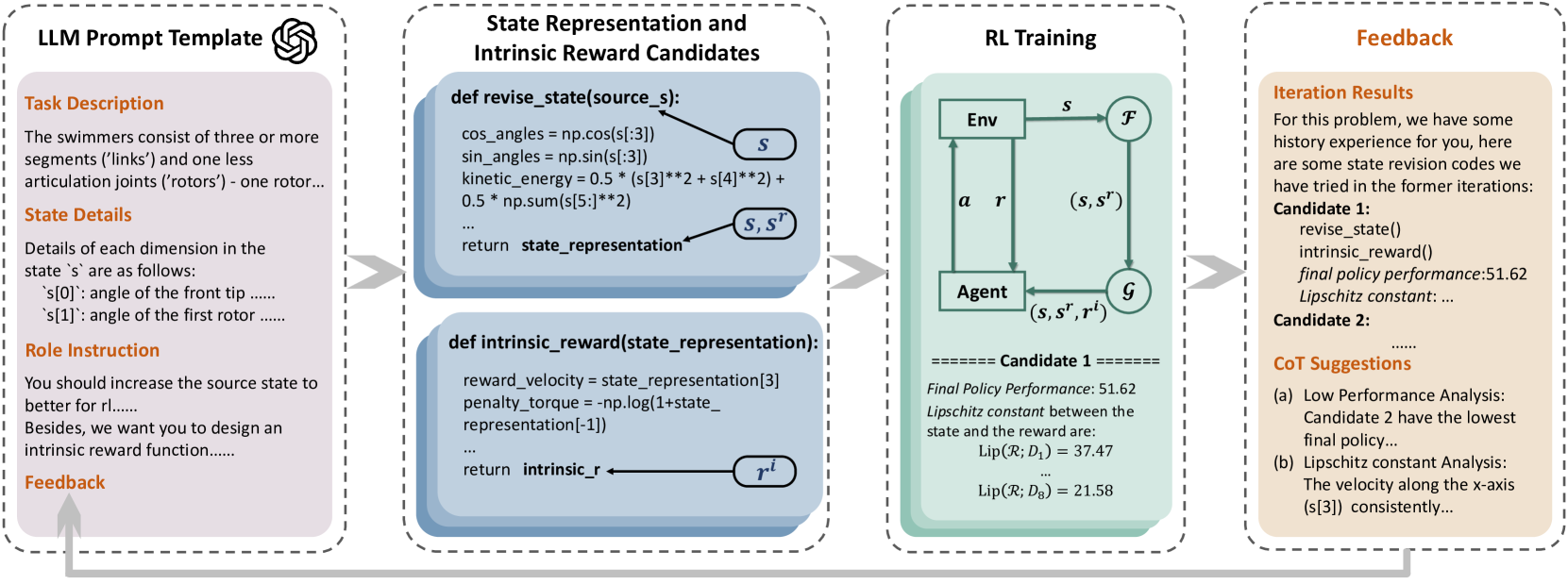
Problem Statement
定义MDP为, 其中是转移函数, 是初始状态分布, 是discount factor. 目标是学习一个RL policy , 最大化reward expectation:
定义Lipschitz constant: 假设数据空间, 标签空间. 有训练数据集, 其标签为, 其中是基于概率分布从的采样, 函数是一个映射Lipschitz constant, 该常数定义为: $$
LLM-Empowered Statement Representation
基于LLM嵌入的广泛的知识和先验信息, 使用LLM生成state repr.
prompt输入分成4个部分:
- Task Description: 当前任务的描述
- State Details: 原始state的每一个维度所代表的含义
- Role Instruction: 要求LLM生成任务相关的状态表达和intrinsic reward代码
- Feedback: 历史信息
目标是通过LLM生成一个python函数, 将原始空间的state()映射到LLM-Empowered state representation() space中. RL训练时, 显式将原始state和LLM-Empowered state拼接()作为observe variable.
生成之后, 使用LLM基于函数再次生成一个reward function , 这个reward函数接收拼接后的, 生成一个reward.
因此, 目标为
Lipschitz Constant for Feedback
Explanation
Lipschitz constant表征一个函数的平滑性. 对于一个函数(映射)而言, 其Lipschitz constant计算方式为:
需要区分映射和Lipschitz常数.
为了增强状态表示的鲁棒性, 多次迭代query LLM, 包含先前的训练结果作为Feedback. 每个training iteration, 从LLM中采样K个state representation和intrinsic reward function code . 然后在时间步中同步进行K个训练, 用于评估.
Continuous Extrinsic Reward Scenarios:
- 对于一条给定的轨迹 , 其中表示的第维度
- 定义针对给定轨迹的Lipshcitz constant array: 其中, 是将映射到extrinsic reward(不是上面提到的intrinsic reward)的一个函数. 每一个维度都有一个映射, 一共有个. 因此
- 使用更新全局的:
- 在每一个training iteration结束时, 将和policy preformance作为Feedback提供给LLM, 根据Feedback调整生成的函数
LESR with Discounted Return:
将的每一个维度映射到dense extrinsic rewards. 但是对于sparse reward settings, 将这些extrinsic rewards替换成discounted episode return .
LESR with Spectral Norm:
使用Lipschitz constant可以降低的上界, 改善value function的收敛性, 因此使用spectral norm去估计. 通过计算value function的权重的spectral norm, 可以近似得出, 这里的是spectral norm.
Spectral Norm
谱范数是矩阵最大奇异值, 记为.
几何意义: 矩阵对于输入向量的最大拉伸程度