Video Tree
Paper
motivate:
- 信息冗余, 大量查询无关信息
- 查询没有粒度的区分. 部分信息密集区域可能需要更细粒度的时序理解
Method
Adaptive Breadth Expansion
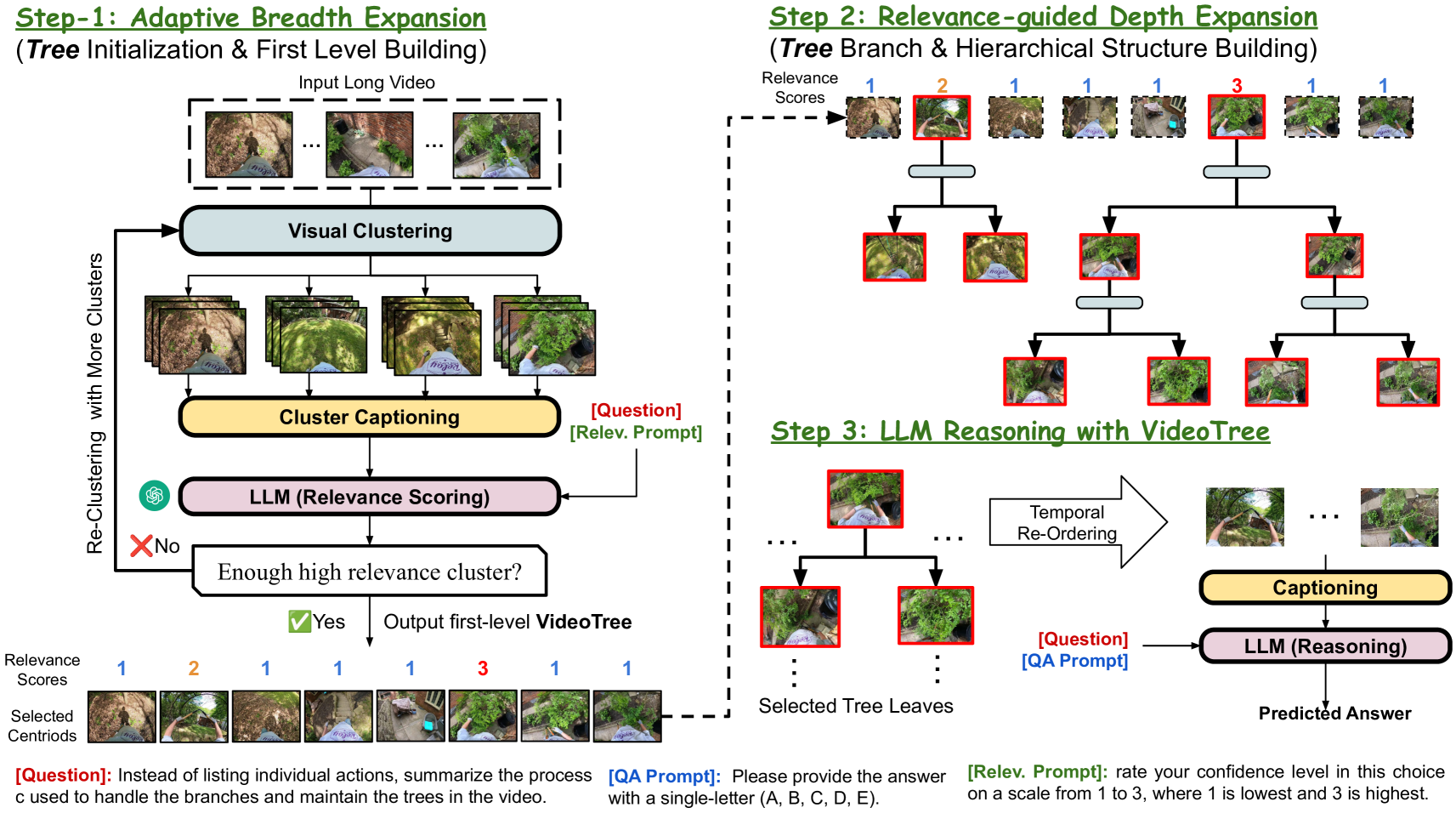
Visual Clustering
根据semantic similarity对视频帧进行聚类以减少冗余.
定义视频帧序列, 其中是时间步处的frame, 是视频长度. 使用pretrained visual encoder (EVA-CLIP-18B) 提取features . 然后使用K-means根据features进行cluster.
Cluster Captioning
使用Captioner对每一个cluster的keyframe(cluster中心的frame)或者keyframe及周围的frame转换为文本描述, 将这些文本描述作为相应cluster的关键语义描述.
Relevance Scoring
使用LLM的推理能力来评估提取信息是否足以回答给定的query.
- 输入: Captioning 和query .
- 输出: 相关性分数, 是第个cluster的分数. 分成三个级别:
- not relevant
- somewhat relevant
- highly relevant
设置, 作为阈值, 决定Adaption过程是否停止. 设置聚类数量的最大值以避免无限循环.
Relevance-Guided Depth Expansion
对于Somewhat Relevant的cluster, 将其重新聚类成个sub-cluster, 为树的branch width.
对于highly relevant的cluster, 将其重新聚类成具有宽度的两级树, 同时保留前一级别的信息
LLM Video Reasoning
inference的时候, 从树的root节点开始遍历, 扩展到叶子节点, 从tree的所有cluster中提取keyframe, 并使用captioner生成caption. 然后将这些keyframe的caption按照时间顺序排序, 并连接成一个视频的文本描述.
最终, 向LLM提供基于文本的视频描述.