ConRFT
Paper
在fine-tuning一个VLM使其执行robotic manipulation的时候, 可能会由于 有限且不一致 的demonstrations(特别是在contact-rich的环境中), 导致无法得到robust performance
问题:
- 在fine-tuning中严重依赖于数据集的质量与数量
- VLA需要有安全性和成本限制
提出reinforced fine-tuning:
- offline阶段, 使用监督学习(BehaviorClone)+Q-learning结合
- online阶段, 通过consistency policy的方式进行RL训练
Problem Setup and Preliminaries
定义:
- 是pretrained VLA model, 可以编码visual input(如, RGB image)以及language instructions
- : 是任务的trajectory
- : negative log-likelihood 或者Mean-Squared Error
在SFT(Supervise Fine-Tuning)任务中, 目的是用一个小的labeled demonstrations集合作为训练数据.
VLA目的是, 即最小化loss(NLL或者MSE)
定义MDP:
其中是state, 是action. 定义是environment transition probability. 是初始状态分布. 是reward, 使用作为discount factor. 作为policy, 需要maximize reward
Method
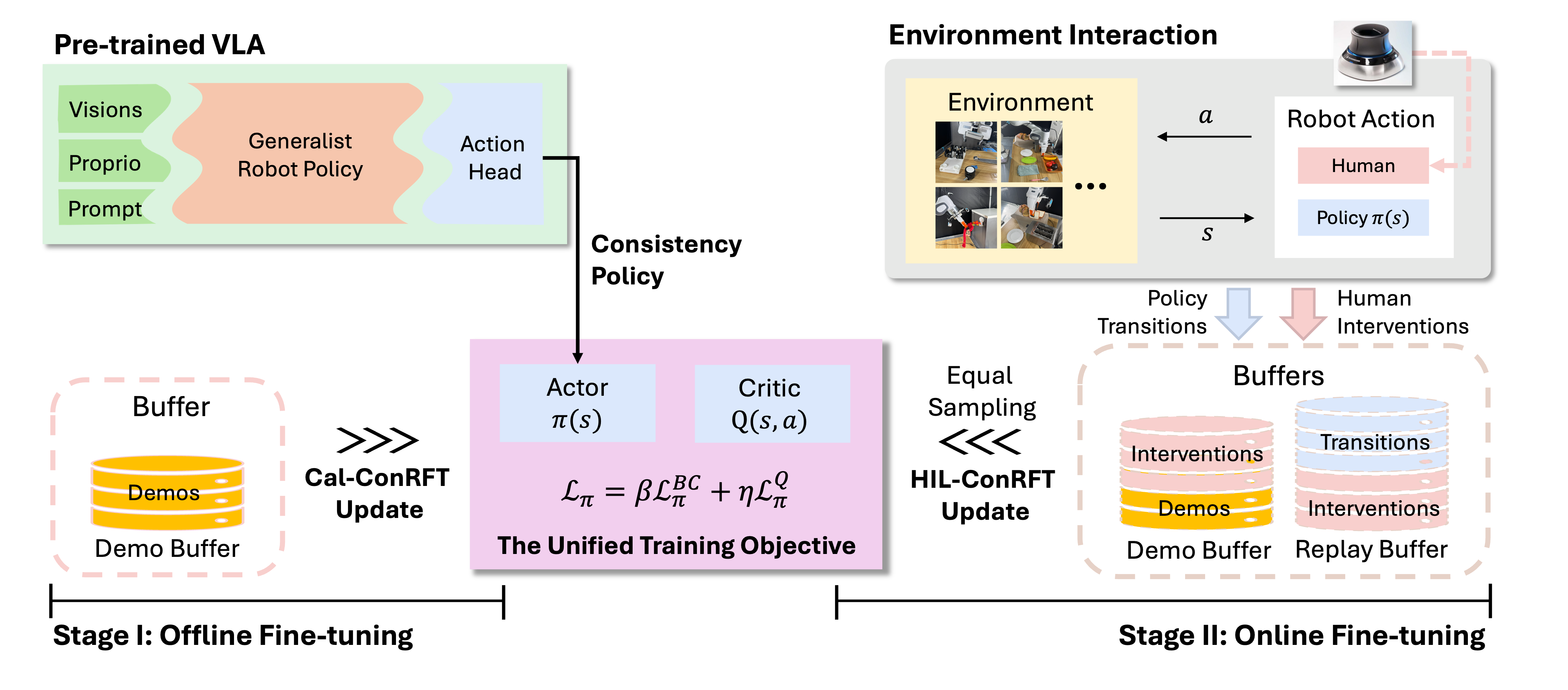
Stage 1: Offline Fine-tuning with Cal-ConRFT
pretrained VLA对zero-shot的novel robotic configurations缺乏泛化性, 因此在online之前, 使用小数据集的demonstrations(20-30 trajectory)
Cal-QL (最开始的方法)
为了让Q-function对 out-of-distribution(OOD) 的action也能robust, 使用calibrated [09-RL#q-learning|Q-Learning]进行训练(通过TD Learning加上一个正则化项)
正则化项惩罚超过在OOD的action上Q-value超过reference 的情况
loss:
其中:
- 是使用作为参数的Q-function
- 是delayed target Q-function parameterized by
- 是Bellman backup operator
- 是数据集或者叫replay buffer, 收集所有的demonstration
- 是控制conservative(保守性)的惩罚
但是Cal-RL是由small dataset(20-30 demonstrations)进行训练的, 因此policy可能难以泛化到从未见过的state.
为了解决这个问题, 引入BehaviorClone loss(BC loss)来让model模仿演示中的行为, 提供了额外的supervisory signals(监督信号)
将BC loss和Cal-QL结合在consistency-based objective中, 提出了Cal-ConRFT的方法. 这个方法使用consistency policy作为action head来fine-tuning VLA, 解决两个主要的问题:
- pre-collected dataset中的inconsistency和sub-optimal的演示示例
- 与Diffusion policy相比, 这个方法更加轻量级
对于diffusion horizon(diffusion的时间范围) , 将其离散化为个子区间, 其边界为. 这种情况下的consistency policy为:
其中:
- 是参数化的consistency policy model, 从步噪声生成action
- : diffusion noise step
- : 经过步加噪声之后的action
- : encoded state, 由参数化的pretrained VLA生成
那么consistency-based objective为:
其中:
-
- 表示欧几里得距离
- : 超参数
Stage 2: Online Fine-tuning with HIL-ConRFT
offline stage提供了初始化的policy, 但是由于其从small dataset中学习, 因此可能有limited performance
提出HIL-ConRFT, 通过与真实世界互动, 使用consistency policy来fine-tuning VLA
训练过程中, offline的数据集仍然保存, 同时使用replay buffer 来保存online数据, 使用symmetric sampling对每一个batch采样(每一个batch在和中等量采样), 目的是减少offline的distribution-shift问题
因此直接的loss为:
使用consistency policy的loss为:
其中:
注意到这个和stage 1的consistency policy loss非常接近, 这可以快速的进行训练(代码修改少)
在online阶段, 降低增加:
- 确保policy能够不遗忘演示数据(continues to align with demonstration data)
- 降低BC loss以防止突然崩溃, 导致安全问题