OpenVLA-OFT
Paper
motivate: 解决问题:
- VLA+LoRA可以实现低参数高效finetune, 但是推理速度太慢(3-5 Hz), 无法满足高频控制的需求(25-50+ Hz). 使用更好的action tokenization能够有 2-13 的加速, 但是两个chunk之间的延迟(750ms)是对真实世界部署的限制.
- 在双臂(bimanual manipulation)任务中, 表现往往难以满足期望.
使用OpenVLA作为基本模型.
三个key design choice:
- action decoding scheme:
- 自回归
- 并行生成
- action representation:
- 连续
- 离散
- learning objective
- next-token prediction (Transformer, LLM)
- L1 Regression (回归)
- Diffusion
结论:
- 并行解码+action chunk能增加推理效率, 也能增加成功率, 同时使input/output更加灵活
- 连续动作空间更好
- 使用L1 regression进行fine-tuning VLA效果更好(相比于diffusion-based), 收敛/推理速度更快
使用FiLM对文本进行增强
Preliminaries
Action Chunking:
可以提高成功率
但是使用OpenVLA的auto-regressive的范式推理速度太慢(0.33s/token), 因此使用其他的方法做action chunking
Studying Key VLA Fine-Tuning Design Decisions
VLA Fine-Tuning Design Decisions
问题:
- 推理速度慢
- 双臂效果差
比较了一些不同的方法(Introduce的3个key design choice)
Implementing Alternative Design Components
基础的OpenVLA是使用了离散的 token + auto-regressive generation, 用next-token prediction进行训练. 本文使用一些其他的方式进行fine-tuning
Parallel decoding and action chunking:
并行解码允许在一个简单的forward过程中, 将input embeddings映射到predicted output sequence.
修改模型, 使其接受一个空的action embeddings, 然后通过causal mask和bi-directional attention去允许同时预测所有的actions
Bi-directional Attention
Continuous Action Representation:
有两个不同的方法:
- 使用类似ACT的方式, 将decoder最终的输出层连接到一个MLP, 然后得到连续的action
- 使用Diffusion Policy的方式进行denoise, 得到最终的continuous actions
Augmenting OpenVLA-OFT with FiLM for Enhanced Language Grounding
Challenges with Language Following
多个摄像头输入的时候, 可能会陷入spurious correlations(虚假的关联). 训练的时候可能会关注这种spurious correlations, 而忽略掉用户的真正的instruction
用户的输入可能只在某一些特定的时刻有用(比如说, 将勺子放到碗里, 只有在抓起勺子之后才指导robot放入碗中)
FiLM
使用FiLM将language embeddings 注入到 visual representations中, 使模型关注language inputs:
Total Method
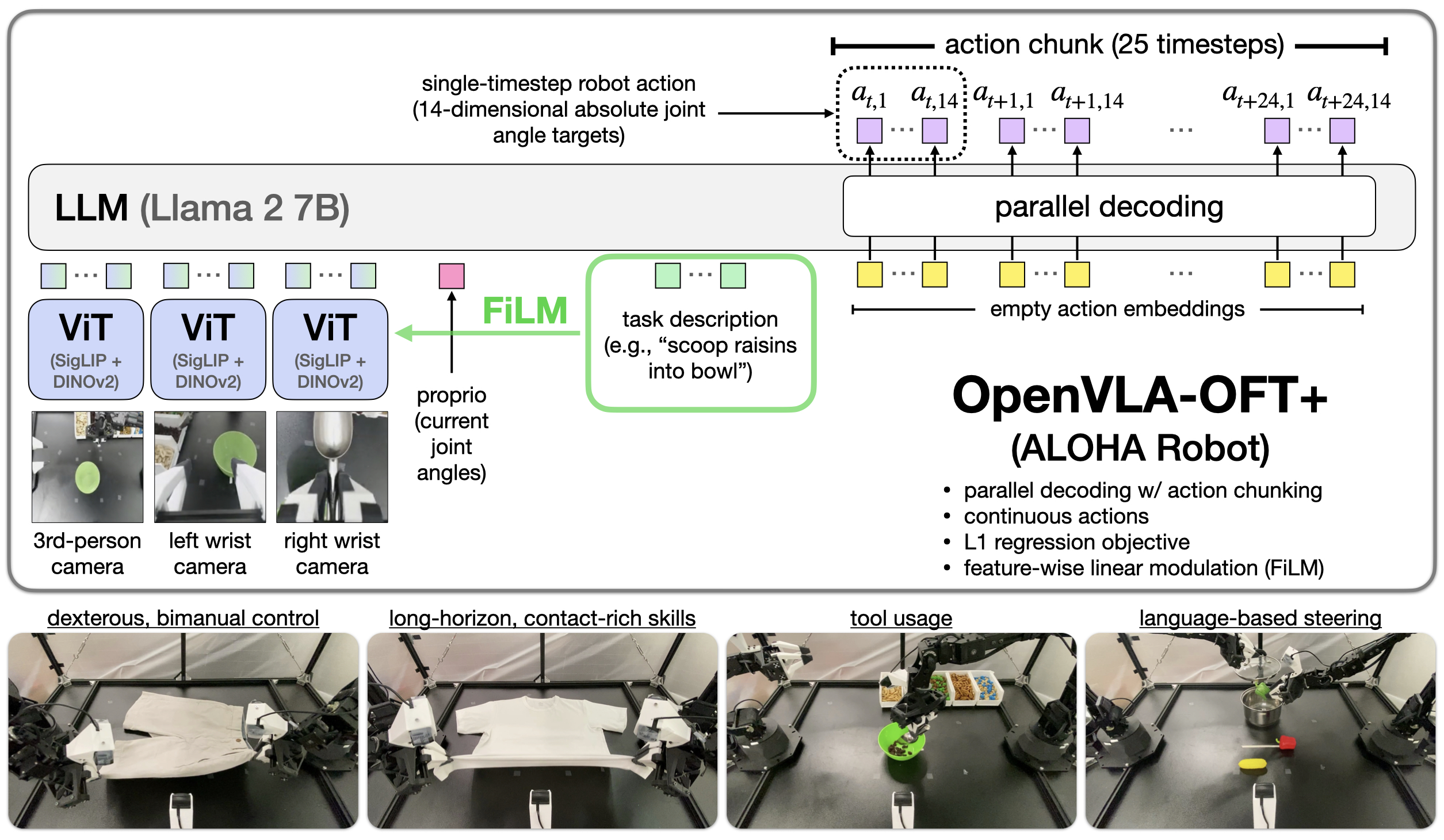
使用了bi-directional attention进行并行解码
解码的最后(最后一个隐藏层), 有两个选择, 一个是使用MLP直接映射, 一个是使用diffusion做denoise