Paper Reading
OpenVLA
—
Related worku
::: block VLM:
- bridge features from pretrained visual encoder(e.g. DINOv2, SigLIP) with pretrained LLM(e.g. Llama) Generalist Robot Policies:
- Octo: policy learning, compose pretrained component, learn to “stitch” them together.
- OpenVLA: end-to-end
- more generalist
- large Internet-scale dataset
- generic architecture :::
—
VLM
::: block
- visual encoder: map image inputs to image patch embeddings
- projector: align image embeddings with word embeddings
- LLM backbone :::
—
OpenVLA
::: block
- concat SigLIP+DINOv2(helpful for improving spatial reasoning)
- projector: 2-layer MLP
- use Llama 2 as backbone
- map continuous action into discrete action token.
- discretize each dimension of robot action separately into one of 256 bins.
- each bin uniformly divided into to quantile
- Training Data: Open X-Embodiment dataset :::
RT-1
—
Preliminaries
::: block Robot learning:
- Aim to learn robot policy:
- sample the action from learned distribution
- target: maximize average reward(indicate complete or not) Transformer:
- sequence model
- map image&text to action sequence Imitation Learning:
- minimize the gap between and
- refine by negative log-likelihood :::
—
System Overview
graph TB a[Textural Instruction]-->|Universal Sentence Encoder|b[word embedding vector] c[images]-->|ImageNet|d[features] b-->|FiLM|e(affine transform) d-->e e-->|Tokenizer|f[Token] f-->|Transformer|g[output Tokens] g-->|Tokenizer Decode|h[action]
RT-2
—
RT-2
::: block Model:
- use CLIP to tokenize images and share embeddings with text
- use PaLI-x and PaLM-E as backbone of VLM
- decode output action token :::
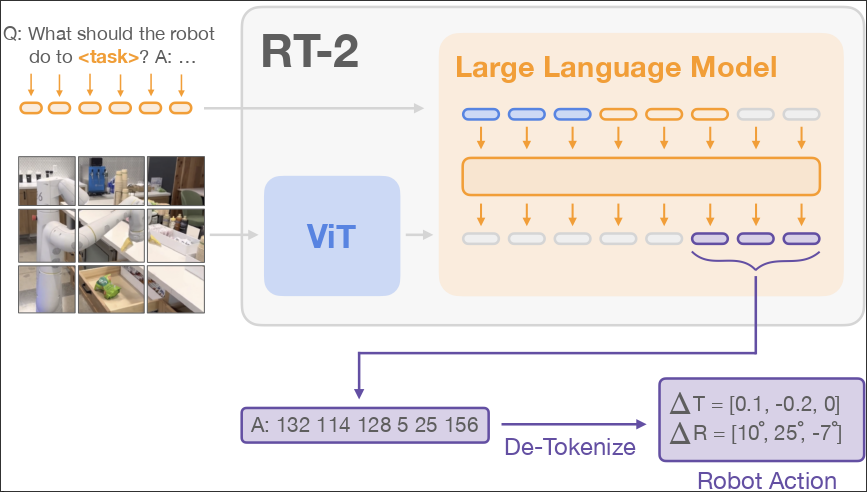
—
::: block Co-Fine-tuning:
- combine datasets: to enhance more generalizing policies
Output Constraint:
- only sampling robot action when prompted with a robot-action task
- otherwise, answer natural language
chain of thought:
- an additional step: Plan Step. describes the purpose of the action that the robot is about to take in natural language first
- then followed by the actual action tokens. :::
RDT-1B
—
Related work
::: block DiT:
- combine diffusion and transformer VLA:
- Vision-Language-Action Model :::
—
Problem formulation
::: block
- : RGB image history
- : low-dimensional proprioception of robot
- : control frequency
- : action, usually a subset of :::
—
Diffusion Model
::: block
-
- use action chunk to encourage time consistency and alleviate error accumulation over time :::
—
Encoding
::: block
- low-dimensional vectors represent physical quantities(proprioception, action chunk, control frequency)
- use MLP with Fourier Features, capture the high-frequency changes
- image input: high-dimension
- use image-text-aligned pretrained vision encoder: SigLIP
- language input:
- pretrained T5-XXL :::
—
Network Structure
::: block
- QKNorm
- RMSNorm instead of LayerNorm
- MLP Decoder instead of linear decoder
- Alternative Condition Injection :::
—
Data
::: block ::: block Physically Interpretable Unified Action Space:
- and
- unified space ::: :::
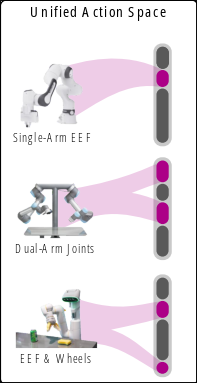
pi0
—
Related Work
::: block Flow Matching:
- denoise by conditional probability path
- loss:
Transfusion:
- train single transformer by multiple objectives
- loss: :::
—
Model
::: block
- model data distribution:
- handle action by action expert, with CFM loss:
:::
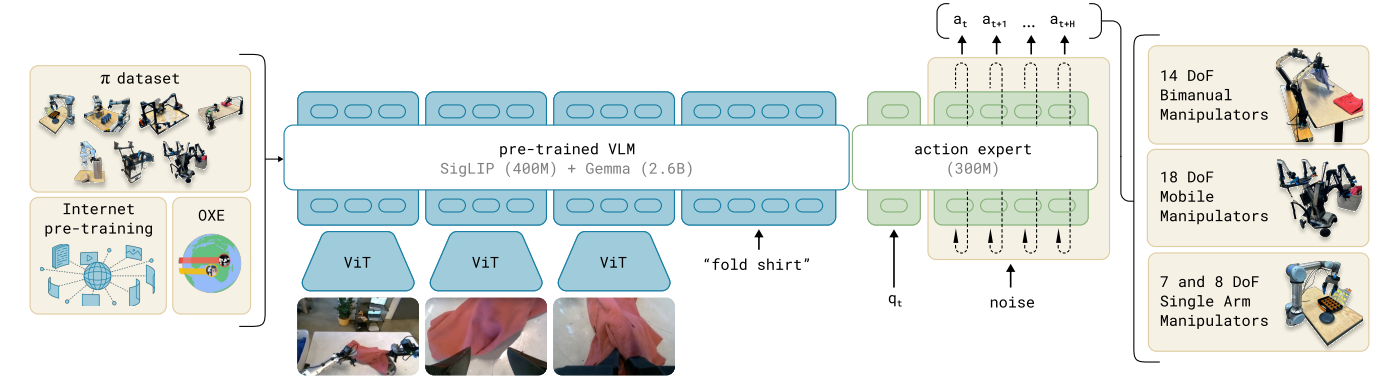
—
Train Recipe
::: block
- first pretrain on big dataset
- then fine-tune with specific task :::