前置: 05-BayesNetwork 06-BayesInference
Probabilistic Temporal Model
Markov Model
graph LR a(X0)-->b(X1) b-->|......|e(X_t-1) e-->c(Xt) c-->|......|d(XT)
假设许多离散的变量(infinity)拥有相同且有限的domain(Domain中的values叫做states),
转移模型展示了state随时间的转移的概率
Stationarity Assumption: 所有时间步上, 有相同的转移模型
联合概率:
Markov Assumption: , 即每一个变量之和自己的上一时刻的状态相关, 与过去的state无关
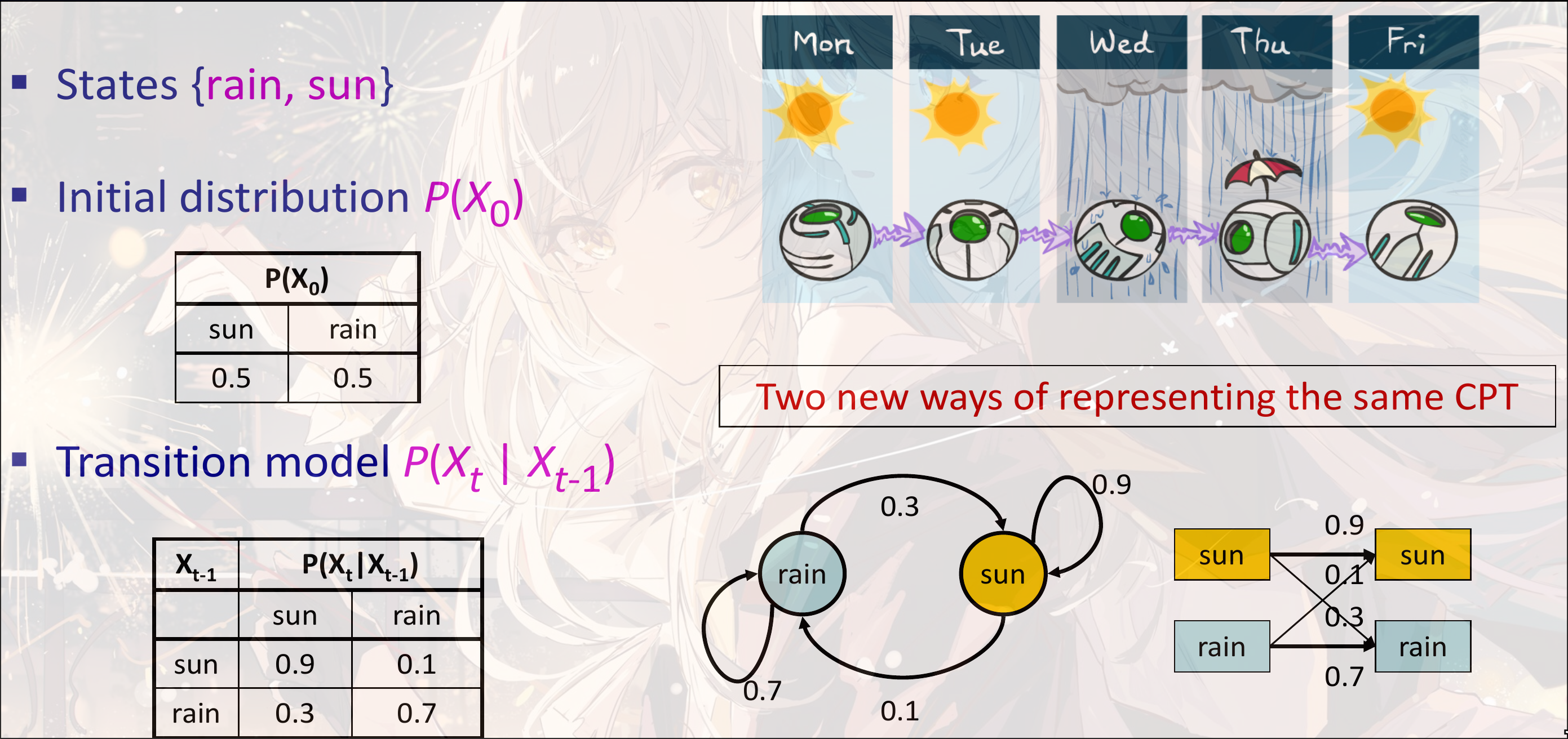
Example
Weather Predict
可以写成, 迭代计算从开始


Stationary Distribution
注意: 随着后续转移次数增多, 状态最终有可能会趋向于一个固定的概率, 无论初始值是什么

因此我们称Stationary Distribution
但是并不是所有的Markov Chain都有Stationary Distribution
Example
Weather

HMM - Hidden Markov Model
只能知道Evidence Variable(或者说, 可观测变量), 但是Markov Chain的state transition是在隐变量上进行的.
graph LR 0(X0)-->1(X1) 1-->2(X2) 2-->3(X3) 3-->i(...) 1-->a[E1] 2-->b[E2] 3-->c[E3]
Model
- Initial Distribution:
- Transition Model:
- Emission Model:
Joint Distribution of HMM:
独立性:
- 给定上一时刻的state, 当前时刻的state与其他时刻的state条件独立
- 给定当前的隐变量, 当前的evidence与其他任何变量条件独立
Inference
规定: 一个标记:
-
Filtering
belief state: 给定目前为止所有的观测变量之后找到当前state的后验概率分布
-
Prediction
在给定目前为止所有变量之后, 计算未来state的后验概率分布
-
Smoothing
在给定目前为止所有evidence之后计算过去的一个state的后验概率分布
-
Most Likely explanation
Filtering
Filtering: infer current state given all evidence
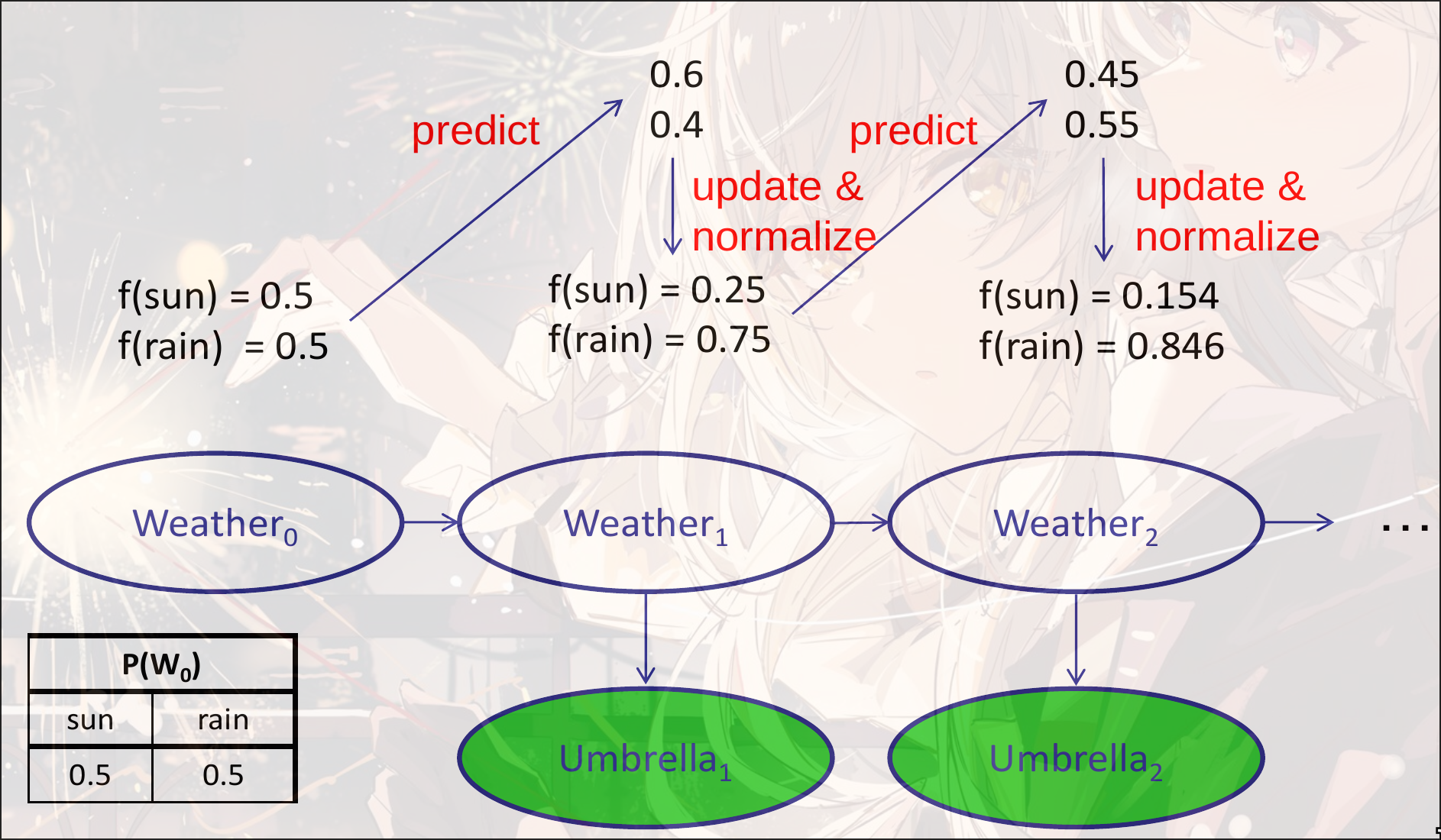
目标: 用迭代的方式求解Filtering
其中是正则化项. 因为已经观测到了和, 所以是一个常量, 不影响概率分布. 因此可以直接写成一个正则化项的形式

假设结果是, 计算过程为. 其中初始化为
时间复杂度: , 其中是state的数量
变量消除:
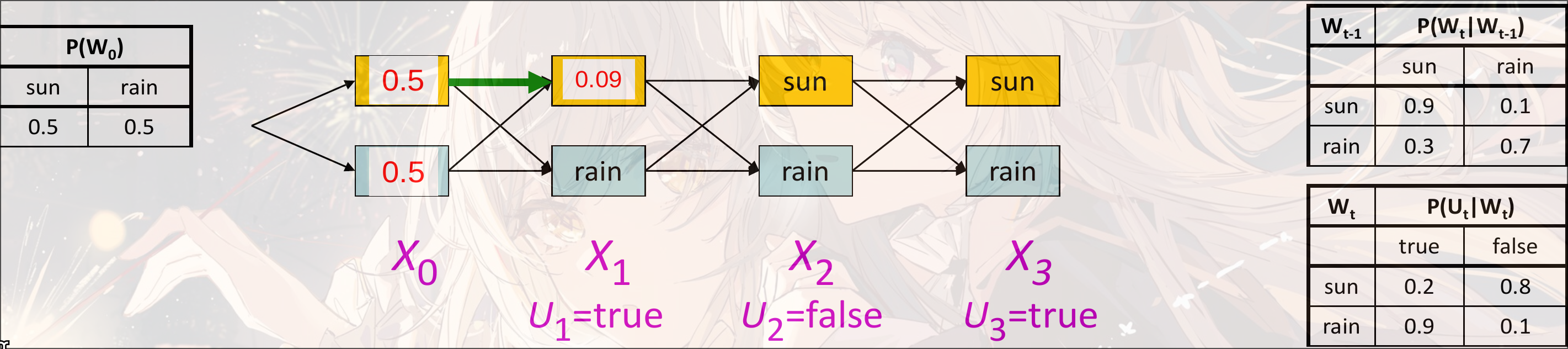
Example
Weather

Another view
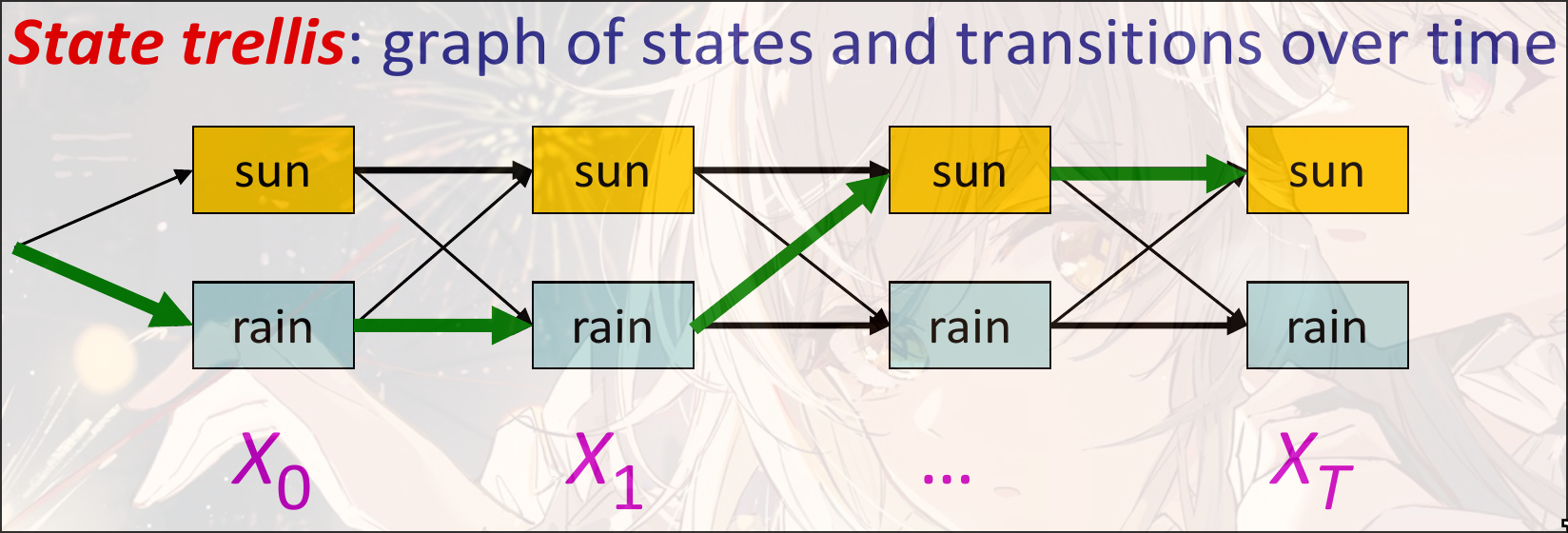
每一个边(Arc)表示一个transition:
每一个边都有自己的weight:
weight的乘积与这个path的路径的概率成正比:
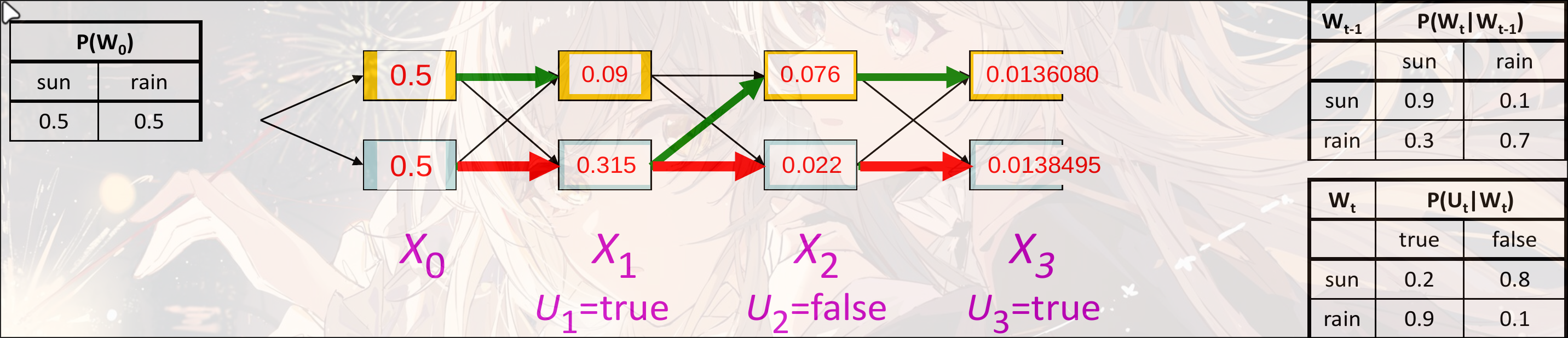
计算新的state: , 类似BFS
使用动态规划的思想: 保存每一个state的概率, 便于计算(用空间换时间, 不用记忆化需要时间, 用记忆化搜索之后时间为):
Most Likely Explanation
维特比算法 Viterbi algorithm. 计算最优路径:
-
Viterbi algorithm
对于时间的state, 记录最大概率的路径
-
Forward Algorithm
求和. 对于时间的state, 记录路径到该节点处的总概率
时间复杂度:
空间复杂度: )
本质上是一个Search. 从根节点出发, 逐层扩展. 保留概率最大的state.
DBN Dynamic Bayes Network
Bayes Network的基础之上, 加上了时间的状态
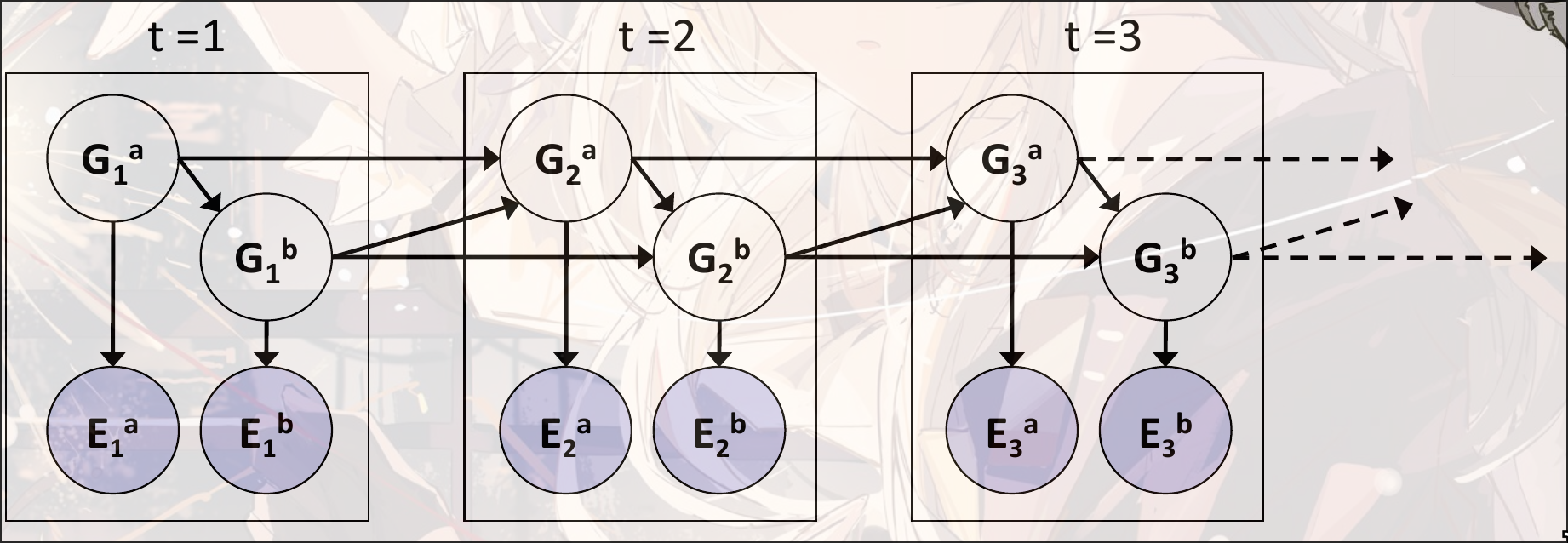
假设后一时态的状态和上一时态的状态有关.
每一个Dynamic Bayes Network都可以被HMM表示. 但是每一个DBN的时态都需要做笛卡尔积.
如: 3个二元变量在HMM中就是一个大小的一个隐变量
优点
依赖稀疏(Sparse Dependencies): 参数量极少
e.g. 假设有20个二元变量, 每一个变量都有两个祖先:
- HMM parameters:
- DBN parameters: , 两个父节点和自己一共八个状态
Exact Inference
Variable Elimination 应用给DBN
-
Offline: 将网络在个时间步上展开, 然后消除变量, 计算得出
但是会导致出现很大的BN
-
Online: 正常展开. 但是每一次展开都消除掉上一时间步中的所有的变量.
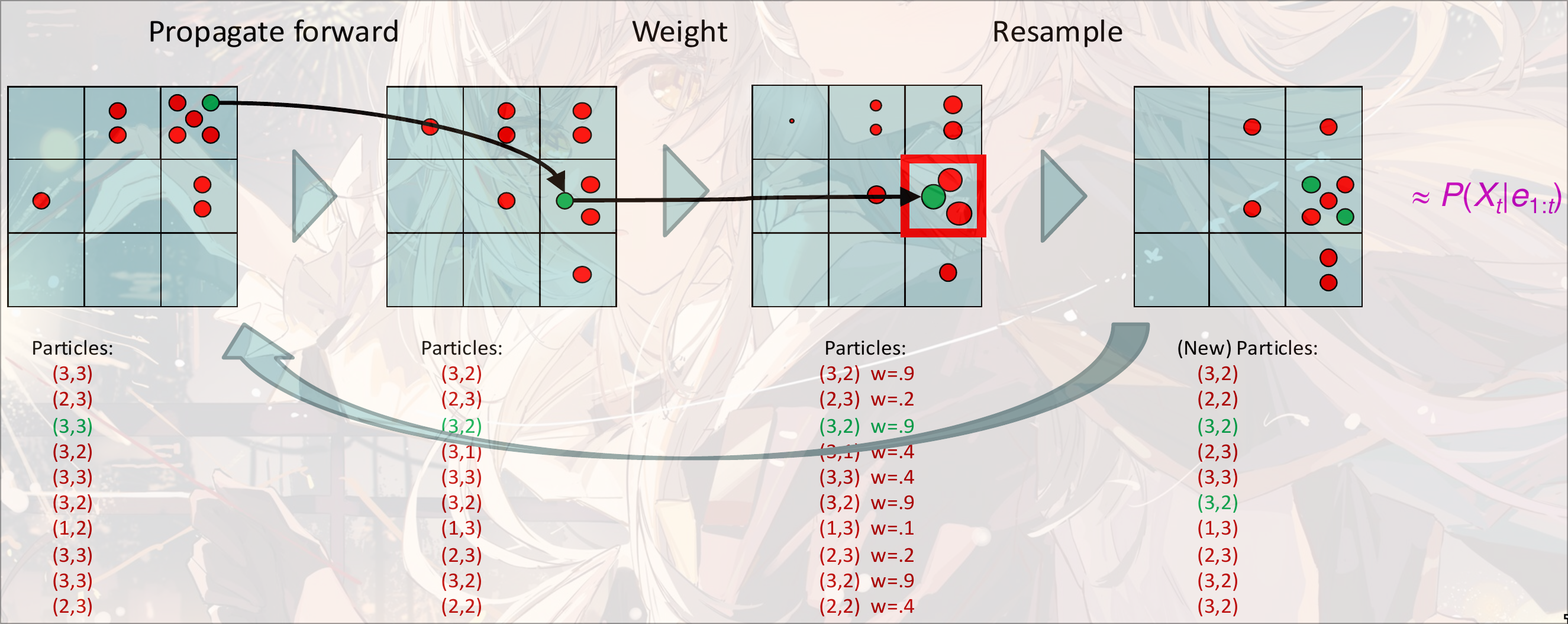
Particle Filtering
对于一个状态空间极大的HMM, 直接进行Exact Inference是不可行的
我们使用approximate inference, 将Evidences看作”下游”, 通过忽略evidence, 直接对Hidden State进行采样. 但是权重会下降非常快, 概率变得非常低, 可能会导致过少的可接受的结果出现.
改进: 使用Particle Filtering
每一个采样的sample叫做一个particle. 初始可以设置成先验分布或者均一分布进行采样. 然后将采样的粒子作为新的概率. 注意, 一般而言, 采样的大小
第一次根据的分布采样. 然后有转移概率:, 当前状态下的权重是. 但是weight在多次之后会变得很小, 会导致每个粒子的权重一直在衰减.
所以进行resample. 在拿到weight之后iou, 根据这个weight重新进行采样新的分布, weight全为1