Multimodal Chain-of-Thought Reasoning- AComprehensive Survey.pdf
Survey of MLLM CoT
Introduce
LLM: Transformer based, token generator
in-context-learning ICL 情境学习: prompt LLM, 无需额外的训练
CoT: prompt LLM使之逐步推理, 或者将复杂任务分解成简单步骤
Rationale: 基于多个Thought支持最终答案
MCoT多模态思维链
Background
将 pretrain-finetune 改成了 pretrain-prompt 框架.
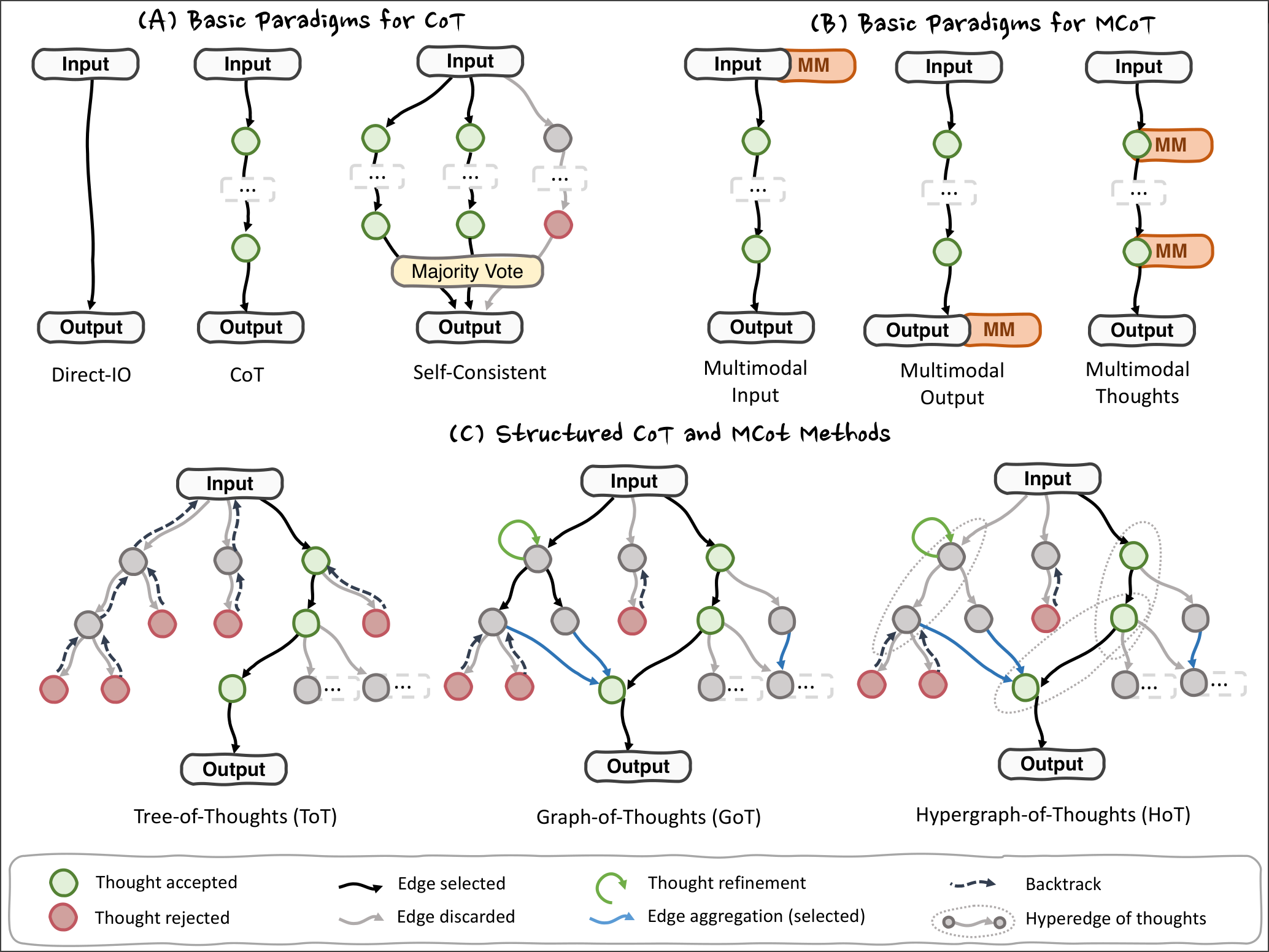
Thought Paradigm:
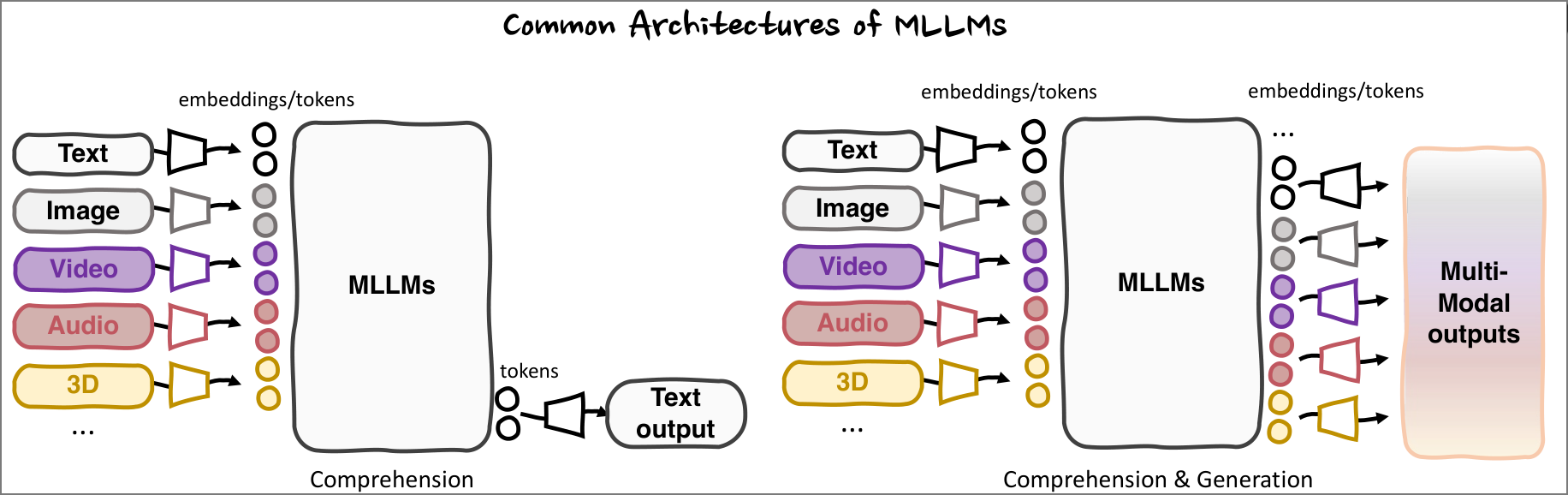
MLLM常见架构:
Methodology
From Rationale Construction Perspective
Prompt-based MCoT
使用包含instruction或者in-context demonstration的prompt来引导LLM生成rationale
一般用于zero-shot或者few-shot的问题. 大多数MCoT都遵循固定的thought step. 部分MCoT使用expert tools
Info
expert tools:
- DetToolChain
- Cantor 是使用其他的网络(Object detect等), 使用其结果辅助MLLM response
e.g. think step-by-step to understand the text and image inputs
Plan-based MCoT
在Reasoning过程中, 动态探索/优化thoughts
e.g.
- MM-ToT, 使用GPT-4和Stable Diffusion去生成Multimodal, 使用DFS或者BFS去选择optimal outputs
- HoT, 跳跃式逻辑推理, 生成Thought并封存在一个hyperedge中
- AGoT, 将多个GoT使用网络aggregation, 然后进行推理
- BDoT, 使用辩论的方法, Positive Side v.s. Negative Side, 最后summarize
- PARM++, image generation过程中使用verification CoT去除bad outputs
Learning-based MCoT
在pretrain或者fine-tune过程中, 添加rationale推理步骤, 显式要求LLM学习.
e.g.
- Multimodal-CoT, T-SciQ: 第一个将rationale作为data进行pretrain的方法 和 refine该方法的方法
- MC-CoT: 在pretrain过程中结合了Self-consistency和voting的方法, 增强小模型的推理能力
- LoT: 使用跳跃思维进行fine-tune以提高创造性
From Structural Reasoning Perspective
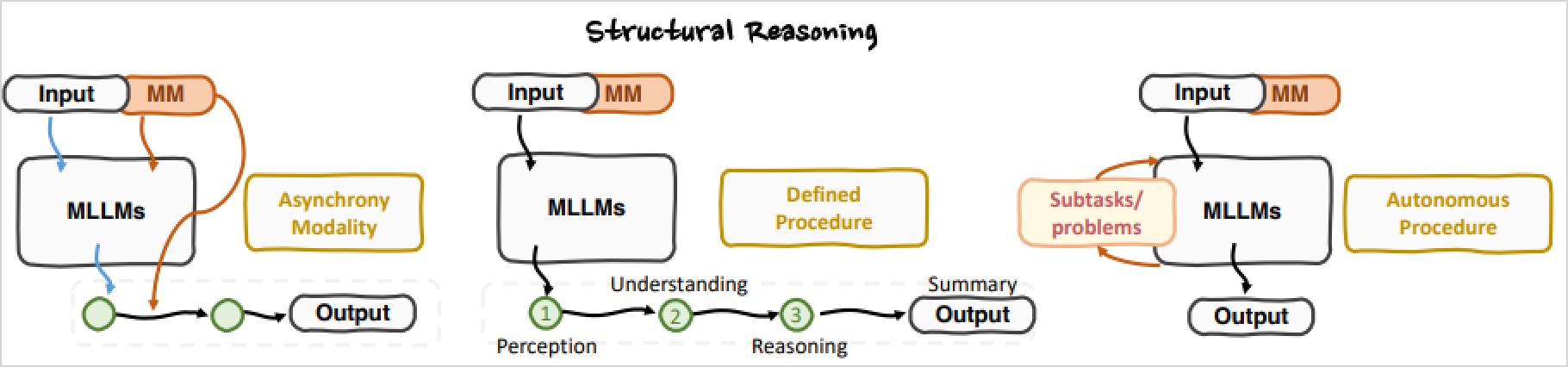
Asynchronous Modality Modeling
将 感知 和 推理 两部分解耦, 异步推理.
Defined Procedure Staging
定义每一个Thought step都干什么
e.g.
- BDoT: 第一步是辩论, 第二步是总结
- 第一步是感知, 第二步是理解, 第三步是推理
- …
Autonomous Procedure Staging
让LLM自主确定每一步需要干什么
From Information Enhance Perspective
- Using Expert tools
- Using World Knowledge Retrieval (RAG)
- Leveraging In-context Knowledge Retrieval
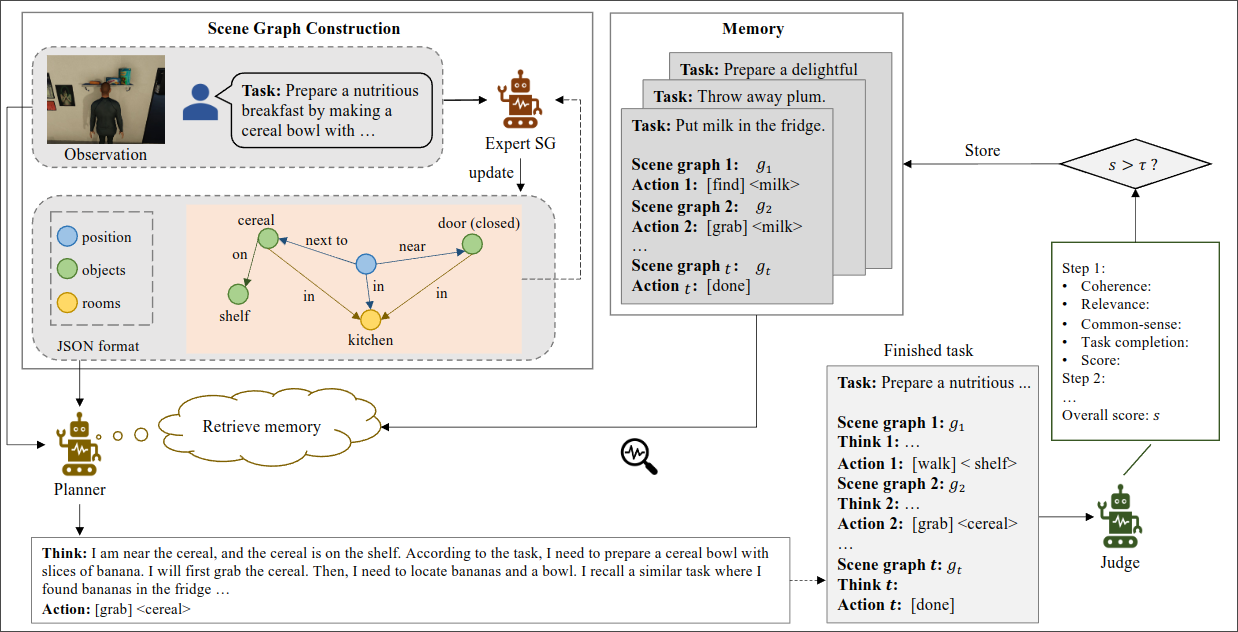
e.g. MCoT-Memory: 建模关系图片中的空间位置关系图
From Objective Granularity Perspective
- Coarse Understanding Level: 粗略理解, 直接对整个图片进行理解
- Semantic Grounding Level: 把RoI框出来, 配合整个图片进行理解
- Fine-grained Understanding Level: 把RoI部分框出来, 放大, 只对这一个部分理解(作为CoT的一步)
From Multimodal Rationale Perspective
- Text Thought
- Multimodal Thought
From Test-Time Scaling Perspective
Slow-Thinking-based Models
外部和内部: 内部慢思考是增强LLM的输出的质量, 外部慢思考是CoT
RL-based Models
- deepseek-r1: 通过使用Group Relative Policy Optimization的方式进行优化, 使其能够进行Long-CoT reasoning
- open-r1: 使用SFT cold starts和iterative self-improvement
- …
RL让LLM无需SFT即可解锁复杂推理和”aha-moment(顿悟时刻)”