LLM generate reward for RL
LaRe
LaRe
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Paper
通过从LLM中整合和任务相关的先验 来获取 语义上interpretable latent reward, 从而增强reward decomposition, 以获取更好的RL
Preliminary
MPD可以定义为, 其中是state space, 是action space, 是discount factor(用于reward随时间步衰减), 是environment state transition distribution. 目标是找到policy 满足最大化reward
对于episodic RL, expected episodic reward是
通常的一个假设是decomposition of the episodic reward:
Latent Reward
Motivation
让reward包含其他implicit factors的表现. 从概念上讲, latent reward的不同dimension表示task performance的不同方向
最终的reward是将latent reward从space 到的投影. 构建新的episodic RL概率模型:
其中是从environment中获取latent reward的函数.
使用LLM能够从冗余的environment information中获取interpretable和multifaceted的task performance metrics, 即latent reward
Framework
Link to original
- 使用LLM生成response, 类似CoT的方法
- 总结生成的回复, 生成总结. 根据总结生成代码, 这个代码是计算latent reward的一个函数. 调用这个函数并传入
observation, action即可计算得出eval_factors.eval_factors指的是一个list, 里面存放所有的reward- 验证latent reward是否是合理的, 能否运行
- 训练一个decoder. 这个decoder相当于是一个加权求和的Linear Layer.
L2R
L2R
Language to Reward for Robotic Skill Synthesis
Paper
使用LLM定义reward parameter以增强RL
Method
Background and Reward Interface
定义MDP问题: , 其中是state space, 是action space, 是reward function, 是动态方程(在经过action之后得到state), 是initial state distribution.
给定奖励函数, optimal controller能找到最大化reward的动作序列, 其中是roll-out horizon
假设reward有特殊的形式, 满足MJPC:
其中
- 是权重
- 是二阶可微的范数(norm), 最小值为
- 是残差, 当的时候达到最优
- 是第项的参数
使用LLM调整和, 自动生成针对不同task的reward
Reward Translator
Motion Description
- 使用Motion Descriptor LLM, 将user input解释和拓展成描述期望的robot motion的自然语言描述
- 可以对比较简单的任务生成reward, 对于复杂任务经常失败
- 但是可以对复杂任务的motion生成description
- 因此使用template, 让LLM直接生成Motion的自然语言description
Reward Coding
使用LLM生成reward function的API调用
Motion Controller
使用Model Predictive Control(MPC).
每一步MPC规划一个sequence的optimized action , 并将其发送给robot. robot执行之后将state返回给MJPC planner, MJPC生成下一步的plan.
Link to original
RL enhance LLM
MAYE
MAYE
MAYE
Paper
RL 增强 LLM 推理能力
Preparation
Data
关注数学推理问题.
分为两个子类型, text-dominant(使用mm_math5k dataset)和vision-dominant(使用geometry3k dataset):
Algorithm
Loss为:
其中
- 是输入的queries的distribution
- 表示sequence of response tokens
- 通过将限制在之内
- 表示估计的的estimated advantage, 表示是否是好token
- 是discount factor, 令取消discount
- 使用k3 formulation, 提供unbiased estimation
令以取消对reward的KL散度的约束, 只应用对policy distribution的KL散度惩罚项
Reward Function
作为Rule-based signal指导RL training
- 正确的answer获得
+1, 错误的answer获得0- secondary language reward: 使用English回答问题
- 防止multi-lingual drift
- 取消format rewards, 不对格式做约束
Model
使用
Qwen-2/2.5-VL-InstructMAYE Framework
Setup
冻结connector(projector), ViT, 只训练LLM backend(Transformer)
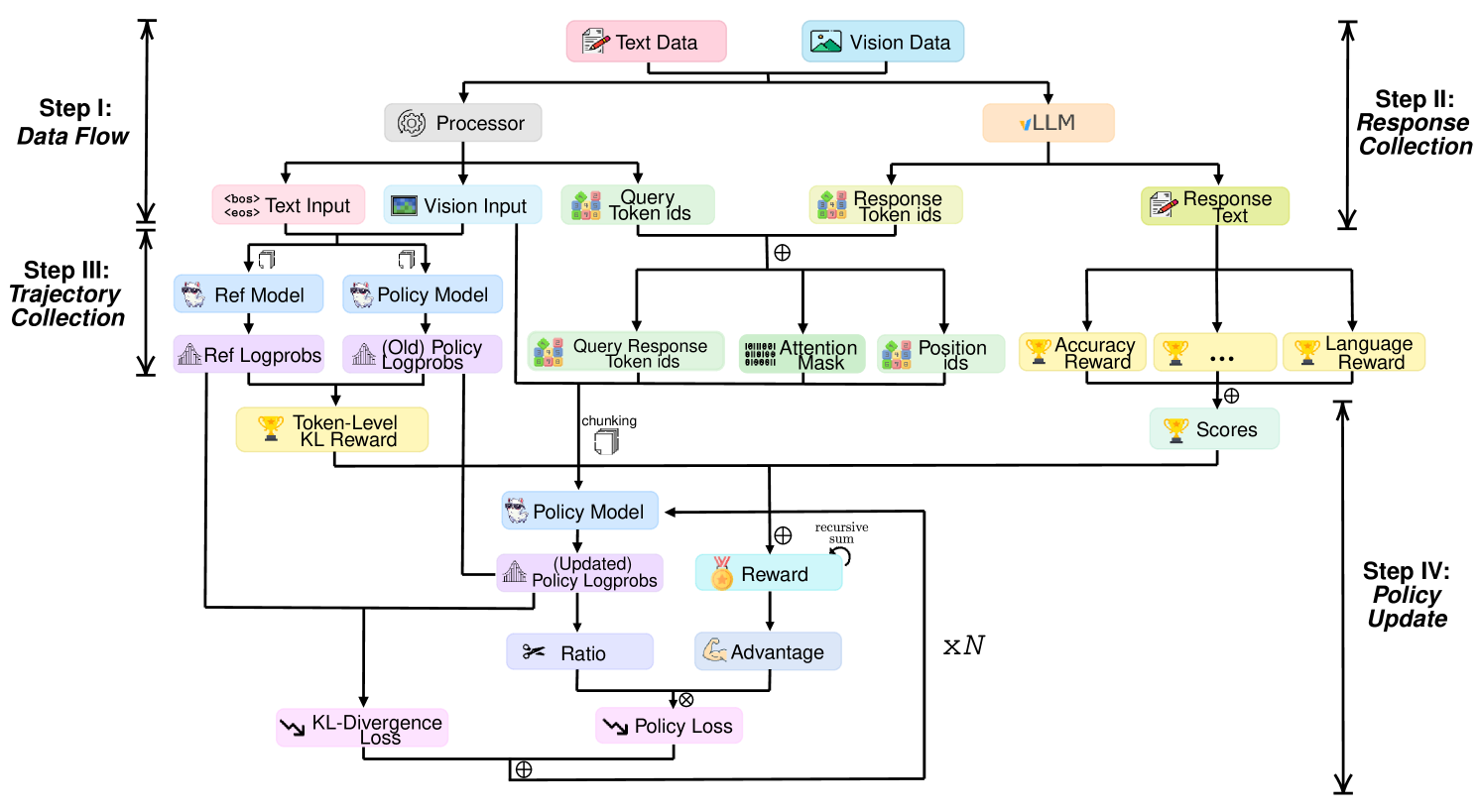
Data Flow
将text data和vision data给tokenize
Response Collection
生成Response. 分布式训练的话会涉及到GPU数据reduce
Trajectory Collection
收集需要的token ids, 拼接query token ids和response token ids, 重新计算attention mask和position encoding
为了防止out of memory, 只保留response的
logprobs, 因为RL用不着query的logprobsPolicy Update
基于保存的trajectories进行RL更新policy model. 使用Algorithm中的公式计算Loss
MAYE Scheme
Training Set Metrics
- Accuracy curves: 反应algorithm和data preparation的正确性和有效性
- Response length: 输出的长度, 反应模型的output pattern, 包括细节和推理深度的等级
Validation & Test Set Metrics
- Accuracy curves: 输出随训练episode增加的准确性曲线
pass@8:temperature=1.0,top_p=1.0, 评估上限pass@1:temperature=0.6,top_p=1.0, 评估真实性能, 并防止重复或不连贯的输出pass@1:temperature=0.01,top_p=0.001. 评估真实性能, VLM的基准setup- Accuracy tabs: 最终模型的准确度表格
Reflection Metrics
Link to original
- Words count: “顿悟时刻”(“aha moments”), 反应RL训练的有效性, 通过计算”反思词”(“reflective words”)在generation step中的频率来反映:
["re-check", "re-evaluate", "re-examine", "re-think", "recheck", "reevaluate", "reexamine", "reevaluation", "rethink", "check again", "think again", "try again", "verify", "wait", "yet"]- Ratio curves: 随训练进行, 展示reflective words的频率:
- reflection ratio:
- reflection ratio in correct answers:
- reflection ratio in incorrect answers:
- correct ratio in reflection texts:
- correct ratio in no reflection texts:
ToRL
ToRL
ToRL
Paper
一个from-scratch的RL训练, 允许模型通过广泛的探索找到最佳的工具利用策略
Dataset
数学奥赛级别的问题
Tool Integrated Reasoning(TIR)
使用TIR取代CoT, 增加精准计算能力
使用tool integrated reasoning可以调用外部程序. TIR的一个trajectory为:
其中, 表示自然语言推理, 表示生成的代码, 表示外部得到的结果. 生成过程表示为:
其中query , 是外部的代码解释器
ToRL
将TIR直接与LLM使用RL结合, without prior fine-tuning.
TIR Rollout Framework
使用
Qwen2.5-Math作为Transformer LLM backend当识别到的时候, 会停止输出, 并调用外部程序执行代码, 将结果返回给LLM, 并拼接成, 然后LLM继续生成自然语言
Design Choices of ToRL
Tool Call Frequency Control
防止使用CPU进行执行代码导致GPU空闲时间过长, 设置超参数, 当调用代码次数超过时, 强制使用纯文本推理
Execution Environment Selection
使用Sandbox Fusion, 提供隔离的环境
Error Message Processing
让Sandbox Fusion生成不含有文件的报错信息并只提取最后一行(为了减少上下文长度)
Sandbox Output Masking
计算loss的时候, 屏蔽Sandbox输出(即, )
Reward Design
成功回答问题, reward, 否则, reward
引入基于代码的惩罚: 如果代码不可执行, 则reward
Link to original
Others RL with DL
使用Transformer模仿RL
Think Before You Act
将语言推理和环境中执行action结合起来
Problem Formulation
考虑一个部分马尔可夫决策过程(Partially observable Markov decision process, POMDP), 只包含部分可观测信息.
历史信息, 文本instruction , 目标是找到最优的策略
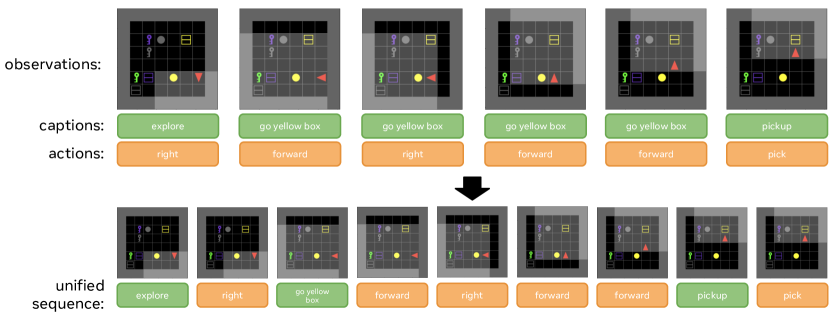
training的时候在预收集的dataset上进行offline的训练. 训练时输入trajectory , 其中m是文本instruction, 是时刻的”字幕”, 但是只在training stage时出现, inference/evaluation stage并没有
Method
Unifying actions and language reasoning
在记录的过程中, 将action和字幕进行统一:
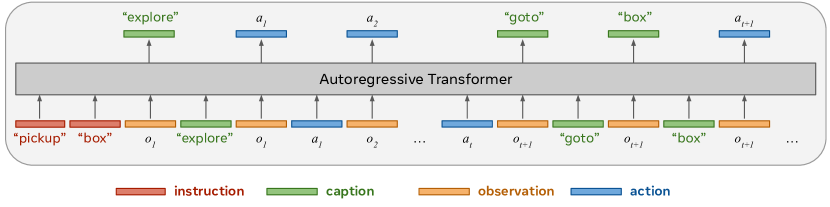
Auto-regressive transformer for generating both language and actions
直接送给transformer进行自回归推理
Experiment
Training details
使用GPT-2, 和对应的tokenizer
将RL蒸馏到DL的神经网络中
In-Context Reinforcement Learning with Algorithm Distillation
将offline RL视为sequential prediction problem, 将RL policy蒸馏到causal sequence model中, 使用DL对RL建模