Paper
基于pi0的改进版
设计训练recipe, 以提供breadth knowledge, 使robots在不同级别的抽象层次上泛化
graph TD WebData["Multimodal Web Data <br> (图像、文本、问答、检测)"] RobotActionData["Robot Action Data <br> (来自多种机器人)"] WebData -- "Co-training" --> Pi05("π₀.₅ Vision-Language-Action Policy") RobotActionData -- "Co-training" --> Pi05 UserPrompt["用户高级指令 <br> 'clean the kitchen'"] UserPrompt -- "输入" --> Pi05 Pi05 -- "1.预测高级子任务" --> Subtask["语义子任务 <br> 'pick up the plate'"] Subtask -- "2.作为低级指令" --> Pi05 Pi05 -- "3.生成低级动作" --> ActionExpert(Action Expert) ActionExpert --> RobotAction["机器人动作序列 <br> (连续、高频)"] RobotAction -- "控制" --> Robot(机器人执行)
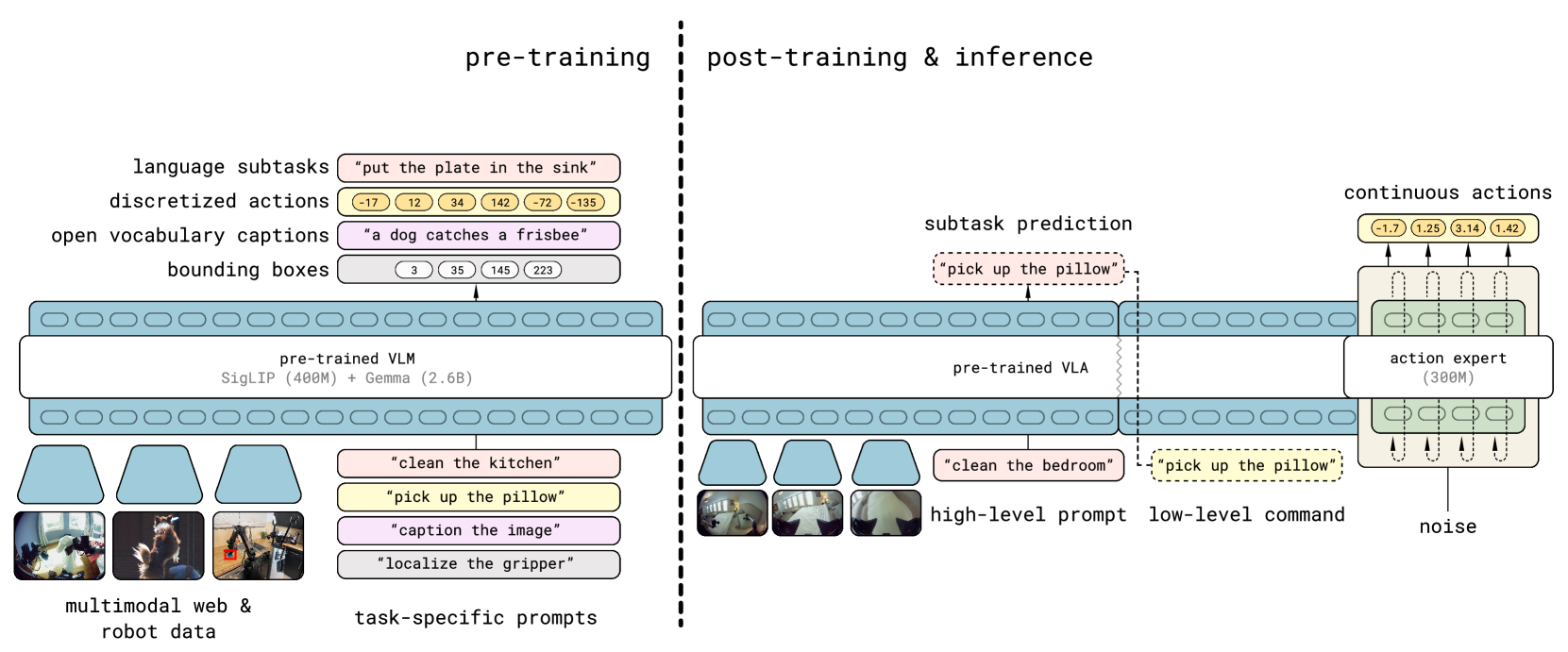
training分成两步
- 将不同的数据(不同的robot的data, high-level semantic(subtask分解), 网络的数据等)混合, 训练VLA, 生成high-level的指导(subtask)
- 在low-level action和high-level semantic actions上进行fine-tune(专门针对移动操作)
inference步骤:
- 首先预测semantic subtask: 根据场景信息和任务结构推断下一步应该执行的行为
- 根据subtask预测robot的low-level action
Preliminaries
VLA的任务: $$ 其中:
- : action chunk或者action
- : 观测state
- : Language instruction
The Model and Training Recipe
大体分为两步. 从一个web-data pretrained VLM开始:
- pre-train: 调整VLM, 使其适应不同的任务
- post-train: 将其专门应用于 移动操作 并 配备高效的test-time推理机制
在pre-train阶段, 所有的robot actions使用离散的token表示, 使之更简单, 可扩展 并 让训练更有效率
在post-train阶段, 给模型添加Action Expert(类似pi0), 使用更细粒度的表达, 实现更高效的实时计算控制.
在inference时, model首先提供high-level的subtask, 然后基于这个instruction使用action expert生成low-level actions.
The architecture
policy: , 其中
- : observation, 包含所有摄像机提供的image 和当前robot的状态
- : language instruction
- : subtask instruction(tokenized)
high-level的policy输出, low-level根据输出actions
这里的attention比较特殊, attention matrix这里, image patch, textual prompt, action tokens使用non-causal attention进行处理, 能够理解上下文
Combining discrete & continuous action representations
和pi0相同, FlowMatching预测连续的action:
使用discrete token对VLA的训练会增大训练效率(参考FAST). 但是在inference的时候, discrete的token会让auto-regressive prediction变慢. 因此一个理想的方案是: 使用discrete token进行训练, 使用continuous token进行inference
分成两个阶段, 用同一个loss函数, 使用超参数进行控制是否训练Flow Matching:
其中:
- : VLM主干, 进行next token prediction
- : action expert, 在后期训练可以认为是flow matching
- : cross entropy loss, 是正常LLM训练的loss(包含FAST encoded action tokens)
- : trade-off factor. 进行pre-train的时候, , 只训练VLM. post-train的时候, 打开action expert(flow matching)的loss权重
在post-train的时候仍然训练VLM的next-token prediction, 因为要保持原来输出token的能力
Pre-Training
使用FAST将连续的动作转换成离散的token
Diverse Mobile Manipulator data(MM):
移动操作数据, 400 hours, 在100个新环境中做家务
Diverse Multi-Environment non-mobile robot data(ME):
在家中不可移动的单/双臂机器人数据
Cross-Embodiment laboratory data(CE):
在实验室中的任务, 包含叠衣服, 摆桌子等等, 在一个比较整洁的环境中
包含开源数据集Open X-Embodiment
High-Level subtask prediction(HL):
将”打扫卧室”等高层级指令分解成”整理床铺”,“调整毯子”等low-level subtask
手动标注
Multi-modal Web Data(WD):
图像描述和物体定位等数据集(Cambrain-7M, PixMo, VQAv2)
dataset settings
为了区分一般token和action token, 使用<control_mode> joint/end effector <control_mode>
类似FAST, 需要将1st and 99th quantile到
Post-Training
pre-train 280k gradient steps之后, 添加flow matching, 并为专门训练移动policy
令(在loss中), 保留文本输出能力(cross entropy loss保留), 附加80k的refine
post-training dataset:
- MM
- ME
- WD: 为了保持模型的视觉能力和文字能力
- Verbal Instruction: 新收集的数据集, 关于用户提供language demonstrations, 选择合适的sub-task commands指导机器人移动
Robot system details
 根据平台的不同, 总体DoF在18-19
根据平台的不同, 总体DoF在18-19