FAST
Paper
问题: 在high frequency控制的时候, 需要预测一个action chunk, 但是由于一个chunk中的action过于相关, 因此VLA可能会倾向于预测重复的action以达到一个比较差的local optima
使用discrete cosine transform(DCT)将连续的action chunk转换成离散的多个cosine函数的加和
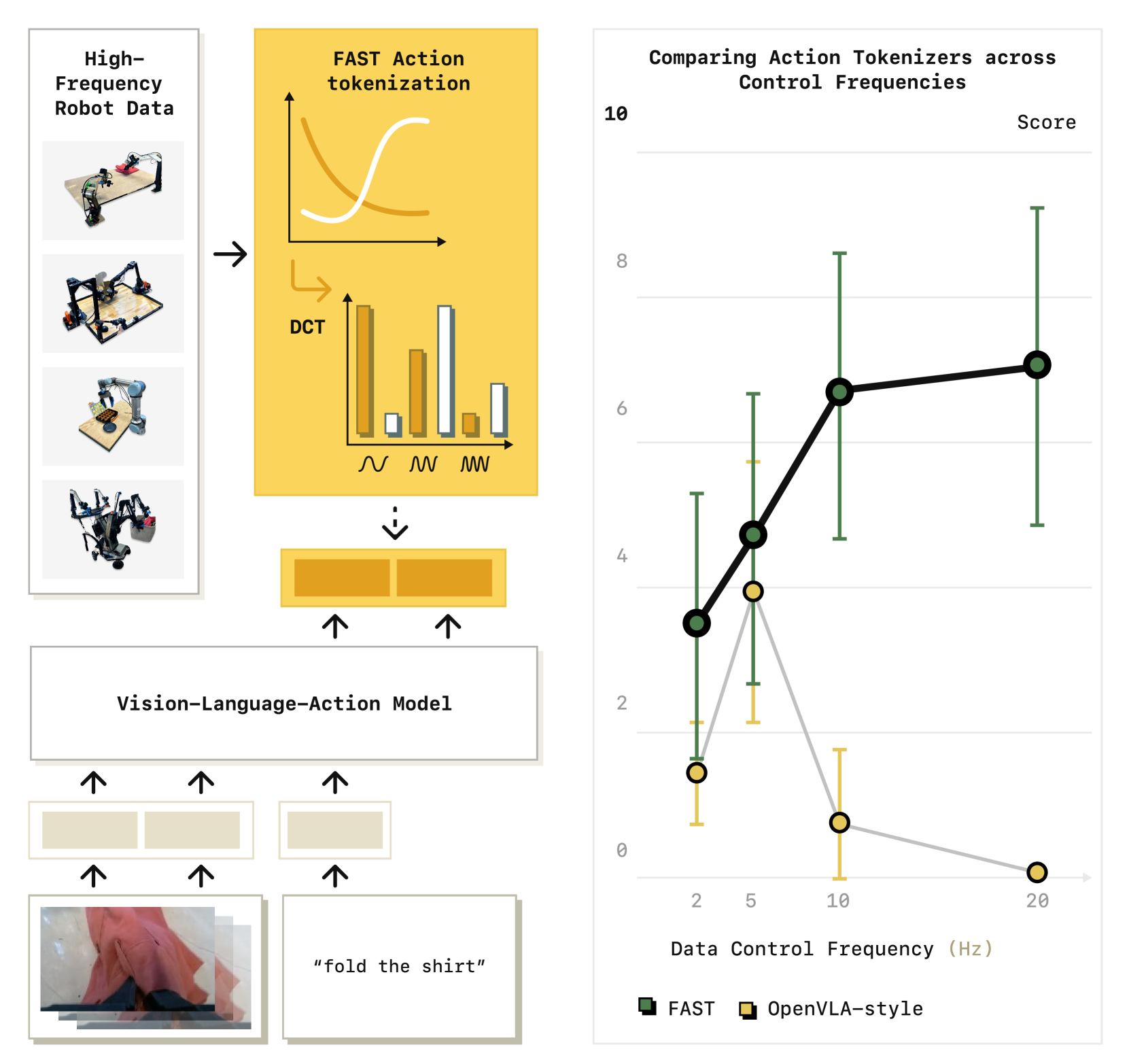
使用离散的token进行训练, Frequency-space Action Sequence Tokenization(FAST), 和pi0集成, 能够在双臂机器人上实现相近的表现, 并且缩短将近5倍的训练时间
Preliminaries
Problem formulation
policy
action tokenizer
由于分词不同, 可能相同长度的action chunk 对应不同的
Binning-based action tokenization
直接将action根据不同的维度分到离散的bin中
问题: 一个action有多个维度, 可能会导致bin太多, 导致训练速度变慢
Case Study: How Does Tokenization Affect VLA Training?
原因:
使用自回归的方式进行next token prediction, 相当于是在给定的情况下预测.
但问题在于:
- 高频信号中, 随着control frequency增加, marginal information趋近于0
- 在平滑信号中, 随时间步的改变, 信号的改变太少
这让训练收敛速度变慢
如: OpenVLA在low-frequency的BridgeV2和RT-1数据集中表现良好, 但是在high-frequency的DROID数据集中表现较差
Efficient Action Tokenization via Time-Series Compression
高频动作轨迹中的冗余信息可能会导致每个动作的边际信息降低
Time-Series Compression via Discrete Cosine Transform
需要考虑训练tokenizer的难易性和inference的速度
选择使用基于DCT的方法
Discrete Cosine Transform
DCT是一种频率空间变换, 将连续的信号表示为不同频率的cosine函数之和
低频分量捕捉信号的总体形状, 高频分量表示剧烈的变化
用简单的几个参数就可以表示一个输入的大部分信息
The FAST Tokenization Algorithm
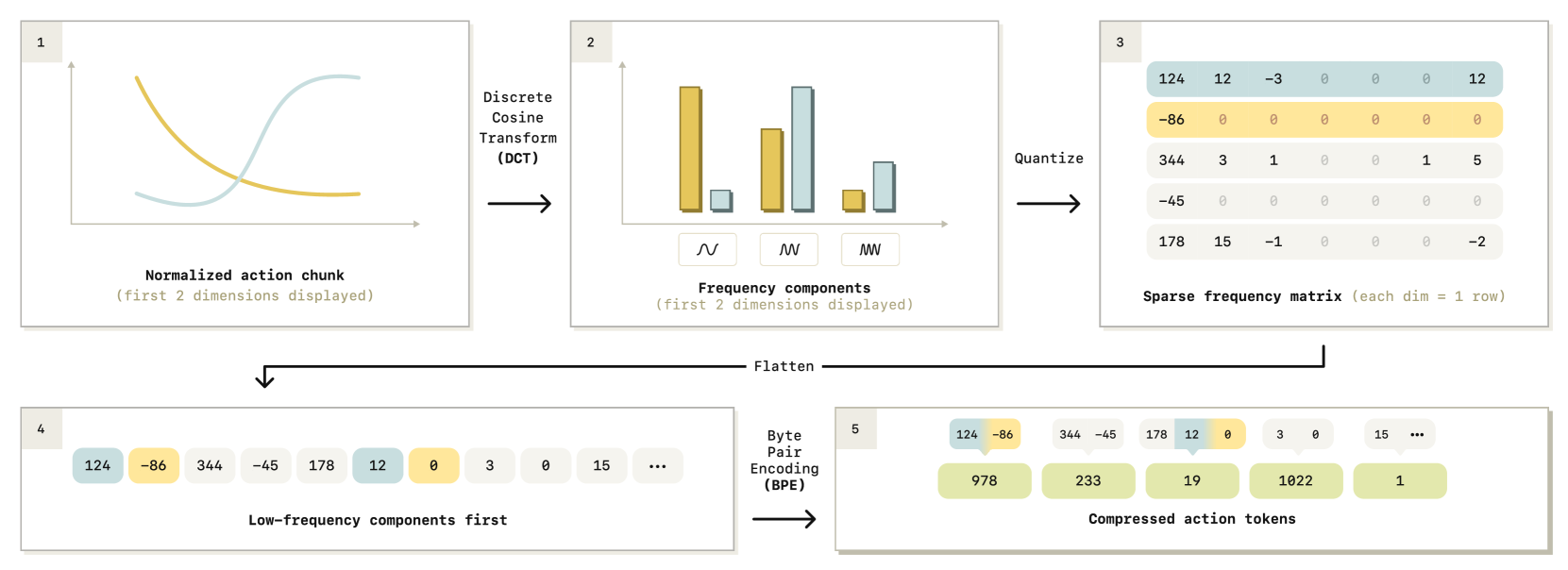
Normalize
将1st and 99th quantile到.
quantile
百分位数, 1st quantile表示整体数据有是小于这个数据的.
如, 有一个1000分数据, 从1到1000. 那么1st quantile指的就是, 99th quantile就是
目的:
- 将数据映射到指定范围, 统一不同的尺度
- (使用quantile而不是将min-max映射到的原因)为了防止数据集中偶然出现的异常情况
DCT
对action的每一个维度应用DCT
为了压缩信号, 进行scale and round操作.
- omit insignificant signals
- scaling coefficient是影响lossiness和compression rate的超参数
tokenize
经过了压缩之后, DCT系数矩阵中大多数都是0, 每个动作维度上只保留了少数显著系数
需要将这个sparse matrix转换成dense token vector:
- 将sparse matrix展平成一个1-dim vector
- 训练一个BPE(Byte-pair encoding) tokenizer, 无损压缩成dense action token
使用BPE能够”压缩掉”0分量, 并能输出vocabulary, 可以无缝集成VLM(VLA)
但是注意, 在BPE之前, 使用不同的展平方法会有不同的效果
- 行优先: 先连接一个action的所有维度, 然后将多个action拼接
- 列优先: 先连接所有action的一个维度, 然后拼接多个维度 (selected)
在autoregressive prediction的时候先预测低频分量(整体形状)能够有更好的表现
使用DCT的方法能够快速的逆向操作(decode), 并且超参数很少(只有两个: scaling factor和BPE的vocabulary size)且超参数对效果的影响很小
使用网络的方法比较繁琐, 并且超参数敏感
实验表明, 使用DCT-based tokenization比VQ-based tokenization效果更好
A Universal Robot Action Tokenizer
唯一需要学习训练的部分是BPE encoder的vocabulary. 但是对于不同的robot, 可能需要不同的训练, 即使训练速度很快(几秒).
因此希望提出一个universal action tokenizer, 能够对任意的robot进行tokenize.
在cross-embodied robot action dataset中进行训练, 有大约100w个的1秒的action chunk, 来自不同的双臂/单臂/可移动robot
实验表明, universal tokenizer的表现和专门针对一个数据集训练的tokenizer表现相近
Code Release
使用AutoProcessor很简单:
from transformers import AutoProcessor
tokenizer = AutoProcessor.from_pretrained("physical-intelligence/fast", trust_remote_code=True)
token = tokenizer(action_chunk)也可以在新的数据集上继续训练:
from transformers import AutoProcessor
tokenizer = AutoProcessor.from_pretrained("physical-intelligence/fast", trust_remote_code=True)
new_tokenizer = tokenizer.fit(action_dataset)