Preserving and combining knowledge in robotic lifelong reinforcement learning
Paper
Introduce
机器人终身学习
基于深度学习的方法, 平衡神经网络的稳定性和可塑性, 这种情况下一个常见的问题是灾难性遗忘. 可以使用正则化, 结构模块化和经验回放, 但是更多应用于传统机器学习
在deep learning for reinforcement learning中, 常见的方法是通过多任务强化学习(MTRL). 在MTRL中, agent可以同时访问多个任务, 避免了神经网络固有的以往问题. 但是也有问题, 依赖与预定义的任务范围, 对zero-shot样本难以泛化.
受到Dirichlet过程混合模型(Dirichlet process mixture model, DPMM)的启发, 结合记忆变分贝叶斯推断模型(memorized variational Bayes inference method, memoVB), 在upstream level实现了simultaneous inference和asynchronous knowledge preservation.
Method
可以continuously gain knowledge from a steam of a one-time feeding tasks.
upstream module包含:
- pretrained language embedding
- task encoder
- DPMM
- generative module 训练过程: offline
- LLM结合语音识别 pre-encoded Language Embeddings. 这一步通过消除计算密集型的实时编码来加速训练
- task state observation(包含end-effector位置, objects的位置, goals的位置)与Language Embeddings结合, 送给task inference encoder
- 生成的inference result使用DPMM与knowledge space进行拟合(fit). 来自同一个任务的inferred result被clustered并储存在DPMM的相同component中. 如果是新的样本, 创建一个新的component来储存. 知识保存:
- 使用task encoder得到的更新DPMM参数.
- 固定DPMM参数, 更新task encoder:
- reconstruct loss: with
- KL divergence: task encoder distribution with DPMM knowledge component
- generative module重建language embeddings并预测当前任务的动态函数, 使得upstream和downstream之间可以解耦参数更新
- 将作为输入, 重建language embeddings tokens, 与原始language embeddings token做reconstruction loss
- 使用当前observed state, action, 进行对下一步state预测, 与真实执行(simulate)后的结果做reconstruction loss
- downstream中使用SAC作为策略学习模块, critics计算, actor提供action
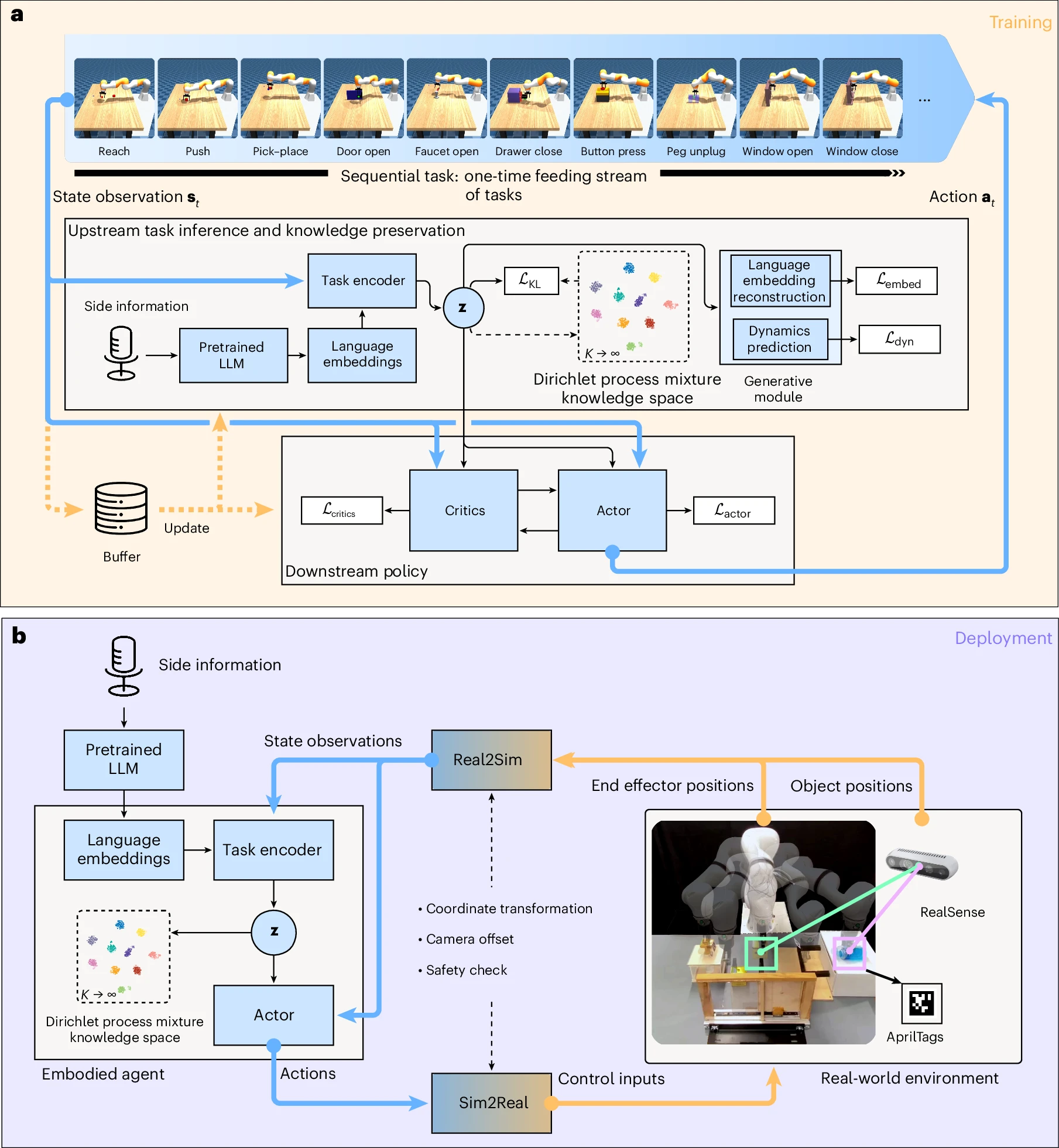
在deployment(inference)过程中, 使用online encode方法. 使用Sim2Real和Real2Sim, 这两个模块包括安全控制检查, Sim和Real world坐标系转换, 手眼校准, 相机偏移设置.
Non-parametric knowledge space
Dirichlet process mixture model
假设为random probability measure, 是base probability distribution基于参数空间, 是concentration parameter.
认为是Dirichlet过程中采样得到, 记作. 使用stick-breaking方法进行从中sample
DPMM用于capture infinite mixture of clusters, 从observation . DPMM的组件并没有固定, 而是online的方式去确定.
DPMM中, 认为每一个数据点, 其中是从先验中独立采样的latent variable, 并通过允许重复来引入discreteness和clustering properties. 因此, 使用相同的绘制的data points自然形成一个聚类.
fit过程中, 为了data point分配给一个cluster, 把data point 和变量关联. 通过来sample得到. 其中混合比例也可以等价表示为从广义的Ewens分布(GEM)中sample.
总而言之, DPMM可以写作:
Variational Inference
使用变分推断来估计真实posterior. DPMM的分布可表示为:
其中是stick-breaking过程, 是对应的随机变量.
使用ELBO方法求近似后验:
基于变分概念和mean-field assumption, 定义的variational distribution:
其中, 是含有变分参数分类因子, 是含参数的stick-breaking比例因子, 是含有参数的base distribution因子.
为了模拟较为精确的后验概率, 使用一个足够大的以包含所有potential features, 则ELBO为:
和需要完整的数据集. 对于大型dataset, 使用memoVB的方法进行批处理.
Parametrics Modules
Language Embedding
human-in-a-loop的方式指导embodied agent完成real-world tasks.
使用RoBERTa将side information(语音输入)encode成embeddings
Observation space
包含end-effector的位置(3-dim), object pose(6-dim), goal position(3-dim)
经过encoder之后, 维度提升为768-dim
Action space
4 dimensions. end-effector的移动(单位: m) 和 gripper的开口距离. 每个维度限制在之内
Reward
success的标准是将object放入goal的范围中.
reward分为:
Optimization
使用Adam adapter.
Metrics
average success rate:
forgetting:
forward transfer:
FT=\frac1{N-1}\sum_{i=2}^NFT_i$$表示从早期任务获取的知识有助于提升后续的任务的成功率 Improvement of few-shot knowledge recall: $$f=\frac1{T\times P_\text{max}}\left(\int^{T_j}_{t_j}P(t)dt-\int^{T_i}_{t_i}P(t)dt\right)表示成功率的最大值, 这里是. 和分别表示在training step 的上下界.