RTC
Paper
问题:
- 由于两个action chunk是分开生成的, 那么在两个action chunk之间可能会有较大的突变
- 在执行结束一个action chunk之后, 模型需要等待下一个action chunk生成结束(同步), 会导致卡顿
- 对推理延时非常敏感(推理时间很大的时候, 可能会: “把咖啡倒在被子里” → “把咖啡倒在腿上”)
解决方案(具体方案在后面):
- 将问题建模成为Inpaint问题
- 异步执行
- freeze一些action
Preliminaries and Motivation
考虑一个action chunk policy: , 把称作prediction horizon
在每一次预测一个action chunk的时候, 执行前个action, 其中, 我们称为execution horizon. 一般比小, 但仍然远大于, 通常.
使用FlowMatching训练的policy, 但是inference的时候也可以使用Diffusion policy.
现在假设是控制器的采样周期, 为生成一个chunk的时间, 定义为推理延时(此处忽略从controller拿obversation的时间)
如果, 那么可以在两个chunk之间无间断的执行inference. 但是现实无法做到: 网络延迟+VLA推理延迟
早期工作是使用暂停, 但会导致卡顿, 并引入training set和inference的distribution drift. 因此要求执行异步inference, 在inference的过程中仍然有action chunk可以执行.
那么假设提前从开始切换action chunk. 由于未知到之间这个action的结果, 可能会导致问题: 两个action非常不匹配(两个chunk可能是不连续的)
Example
这张图表示: 假设第一个chunk是到, 现在假定第二个推理是开始的. 那么第二个chunk 到之间就可能会和真实执行的到有区别. 在切换chunk的时候, 和的差距可能会非常大.
Real-Time Chunking via Inpainting
将这个问题视作”image inpaint”问题, 在给定前面的action的基础上继续生成下一个action chunk
Inference-Time Inpainting with Flow Matching
inpaint是Diffusion和FlowMatching框架的优势.
参考PiGDM和Train free inpaint 算法的去噪步骤:
其中: -: 学习到的速度场
- 目标值. 在inpaint问题中, 这里的是masked image, 期望得到的结果是完整的图像
- 是flow matching的denoise过程, 是最终去噪结束后的原始chunk
- 是mask
- 是guidance weight clipping超参数, 目的是在small number of denoising的时候会unstable
在action生成的过程中, 可以将看成维度为-dim的向量, 其中是prediction horizon, 是action dimension. 那么这个guidance term可以看作是vector-Jacobian product, 可以使用backpropagation进行计算
在计算过程中,
- 训练得到的原始的FlowMatching的vector field . 后面的项的目的是将生成的结果往上面靠近.
- 因为延迟是, 提前个action进行下一个chunk的生成, 那么需要让下一个action chunk的前个action尽可能和上一个chunk的action重合
- 因此让的前个action就是上一个chunk的后个action, 其他的空缺补0 (Question here)
- 使用mask, 只关注重叠的action
- Hard mask: 前个action的权重为1, 其他的权重为0
- Soft mask: 前个action的权重为1, 然后(execution horizon)个action的mask从1到0降低, 其他的为0
- Soft mask的图片如下:
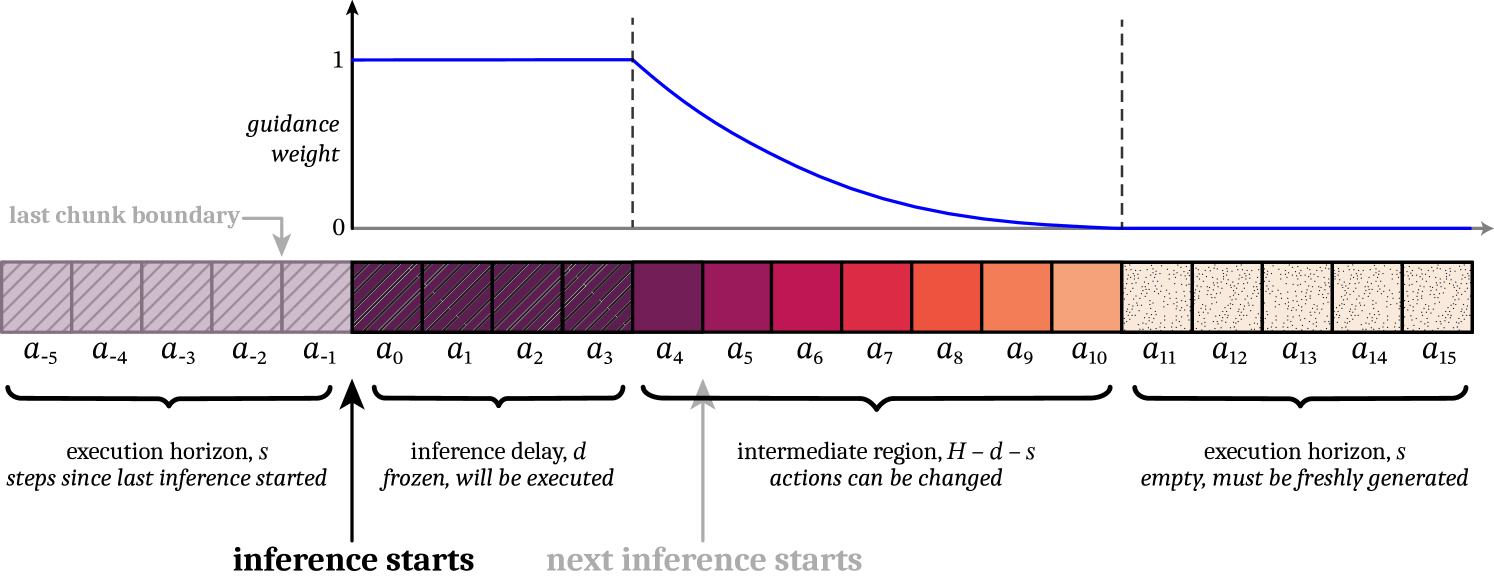
- 计算vector-Jacobian product的时候, 可以使用backpropagation进行简化, 无需计算真正的Jacobian matrix:
- 上述使用pytorch进行编写. 然后对进行求和, 得到
L_pseudo, 调用grad得到结果:guidance_term = torch.autograd.grad(L_pseudo, A_t^τ)[0] - 这里的
guidance_term就是
graph TB subgraph Chunk1 a_m5["a_0"] ==> a_m4["a_1"] ==> a_m3["a_2"] ==> a_m2["a_3"] ==> a_m1["a_4"] ==> a_0[a_5] ==> a_1[a_6] ==> a_2[a_7] ==> a_3[a_8] --> a_4[a_9] subgraph "Actions not executed" a_4-->a_5[a_10]-->a_6[a_11]-->a_7[a_12]-->a_8[a_13]-->a_9[a_14]-->a_10[a_15] end end subgraph Chunk2 subgraph "Action within Delay(executed by last chunk)" a_p0["a'_0"]-->a_p1["a'_1"]-->a_p2["a'_2"]-->a_p3["a'_3"] end a_p3-->a_p4["a'_4"]==>a_p5["a'_5"]==>a_p6["a'_6"]==>a_p7["a'_7"]==>a_p8["a'_8"]-->a_p9["a'_9"] subgraph "Actions not executed" a_p9-->a_p10["a'_10"]-->a_p11["a'_11"]-->a_p12["a'_12"]-->a_p13["a'_13"]-->a_p14["a'_14"]-->a_p15["a'_15"] end end a_10 ~~~ a_p0 a_p15 ~~~ a[next chunk] a_0 -.->|Frozen, weight=1| a_p0 a_1 -.->|Frozen, weight=1| a_p1 a_2 -.->|Frozen, weight=1| a_p2 a_3 -.->|Frozen, weight=1| a_p3 a_3 ==> a_p4 a_4 -.->|Soft Mask, decreasing weight| a_p4 a_5 -.->|...| a_p5 a_10 -.->|Soft Mask, weight near 0| a_p10 a_p8 ==> a a_p5 -.->|Frozen, weight=1| a a_p6 -.->|Frozen, weight=1| a a_p7 -.->|Frozen, weight=1| a a_p8 -.->|Frozen, weight=1| a a_p9 -.->|Soft Mask, decreasing weight| a a_p10 -.->|...| a a_p15 -.->|Soft Mask, weight near 0| a
Soft Masking for Improved Cross-Chunk Continuity
使用exponentially decay降低权重mask:
其中, 是一个与有关的值. 具体的函数样式可以参考前面章节的图